Meltdownのライブパッチ SUSEエンジニアの研究プロジェクト(パート1)
Meltdownは、最近発生した大規模で複雑なセキュリティ上の脆弱性の1つであり、ほとんどすべてのユーザーが影響を受けています。今回は、SUSE社のライブパッチエンジニアとして、この脆弱性の修正が、その範囲と複雑さにおいていかに独特なものであったか説明したいと思います。
Meltdownのライブパッチを作成できるか調査することも、私の目標でした。この調査は、カーネルの内部構造に関する徹底的な研究プロジェクトへと発展していきました。この成果を公開したいと思います。
今回は、4つのパートからなるブログ記事にまとめ、技術的な詳細をわかりやすく説明していきます。これら4つのパートは、毎日投稿していきます。
パート1:ライブパッチの主な技術的障害
パート2:仮想アドレスのマッピングとMeltdown脆弱性。kGraft自体へのパッチ
パート3:アドレス変換バッファー(TLB)フラッシュプリミティブに必要な変更
パート4:結論
Meltdown脆弱性を最初に目にしたとき、ライブパッチの作成は、どのような技法を使用しても不可能ではないとしても、非常に困難だろう、ということがすぐにわかりました。
最大の障害は、この脆弱性の技術的な性質にあります。
- kGraftでは、置換コードへのリダイレクトを行うために、カーネルの関数トレーサー(ftrace)という機構を利用していますが、カーネルには、このftraceが担当していない領域がごくわずかですが存在します。残念なことに、エントリーコード(後で詳述します)もその1つです。リスク緩和のためのカーネルページテーブルアイソレーション(KPTI)のパッチセットでは、このエントリーコードに多くの変更が加えられています。
 kGraftの一貫性モデルは、タスクベースです。kGraftは、新しいライブパッチを適用する際に、遷移期間を開始して、各タスク(思考「スレッド」)を新しい実装に個別に切り替えます。タスクが何も実行していない場合、それらのタスクを置換コードに切り替えるのは、安全であると見なされます。この一貫性の保証は、実用上関心のあるほぼすべての場合に十分であると見なされます。セマンティクスに変更があったとしても、それは通常、局所的な変更であるからです。ただし、KPTIによるアドレスマッピングの切り捨ては例外です。アドレスマッピングは、たとえば、同じプロセスの異なるスレッド間で共有される可能性があります。
kGraftの一貫性モデルは、タスクベースです。kGraftは、新しいライブパッチを適用する際に、遷移期間を開始して、各タスク(思考「スレッド」)を新しい実装に個別に切り替えます。タスクが何も実行していない場合、それらのタスクを置換コードに切り替えるのは、安全であると見なされます。この一貫性の保証は、実用上関心のあるほぼすべての場合に十分であると見なされます。セマンティクスに変更があったとしても、それは通常、局所的な変更であるからです。ただし、KPTIによるアドレスマッピングの切り捨ては例外です。アドレスマッピングは、たとえば、同じプロセスの異なるスレッド間で共有される可能性があります。
最初の障害に関連して、エントリーコードとは何であるか簡単に説明します。Linux環境は、制限された特権しか持たないユーザースペースと、完全な特権を持つカーネルスペースに分かれています。CPUの論理コアは、常に、完全な特権を持つカーネルコードか、制約された特権しか持たないユーザースペースコードのいずれかを実行します。ユーザーがロードしたプログラムコードは、ユーザーモードで実行され、整数や浮動小数点の計算、制御フローの変更、プロセスの仮想メモリへのアクセスなど、ごく限られた操作しか行えません。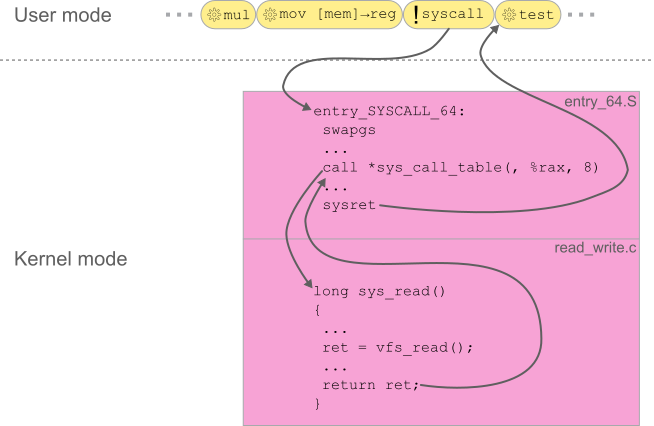 より高度な操作を行う必要がある場合は、カーネルの助けが必要になります。ここで、プログラムは特別な「syscall」命令を発行して、カーネルモードに切り替えるようCPUに指示する必要があります。これによって、CPUはすべての制限を解除し、カーネルのブート時セットアップで指定された固定アドレスに実行をリダイレクトします。このアドレスで実行される命令のシーケンスは、一般に「エントリーコード」と呼ばれます。アセンブリ言語でコーディングされたこのコードの主な役割は、C言語で書かれた後続のステージのために基本的な実行環境をセットアップし、必要に応じて後続のステージで実行される関数を呼び出します。呼び出した関数が戻り値を返したら、エントリーコードは、ユーザースペースプログラムの実行を再開するための準備を整えます。最後に、ページフォールトのような割り込みまたは例外によって、アーキテクチャで定義された別のイベントが形成され、コードの実行がカーネルに移行します。syscallの場合と同様に、一部のエントリーコードの格納場所を示すターゲットアドレスが各イベントに関連付けられます。これらのイベントは、「割り込みディスクリプタテーブル(IDT)」内で編成されます。
より高度な操作を行う必要がある場合は、カーネルの助けが必要になります。ここで、プログラムは特別な「syscall」命令を発行して、カーネルモードに切り替えるようCPUに指示する必要があります。これによって、CPUはすべての制限を解除し、カーネルのブート時セットアップで指定された固定アドレスに実行をリダイレクトします。このアドレスで実行される命令のシーケンスは、一般に「エントリーコード」と呼ばれます。アセンブリ言語でコーディングされたこのコードの主な役割は、C言語で書かれた後続のステージのために基本的な実行環境をセットアップし、必要に応じて後続のステージで実行される関数を呼び出します。呼び出した関数が戻り値を返したら、エントリーコードは、ユーザースペースプログラムの実行を再開するための準備を整えます。最後に、ページフォールトのような割り込みまたは例外によって、アーキテクチャで定義された別のイベントが形成され、コードの実行がカーネルに移行します。syscallの場合と同様に、一部のエントリーコードの格納場所を示すターゲットアドレスが各イベントに関連付けられます。これらのイベントは、「割り込みディスクリプタテーブル(IDT)」内で編成されます。
エントリーコードは従来の関数に含まれていないので、kGraftがエントリーコードをライブパッチに置換できないのは明らかです。これは、kGraft自体が、Linuxカーネルの関数トレーサー(ftrace)を利用していることが理由です。そこで、実行中のCPUに、エントリーコードの新しいアドレスをインストールすることで、同等の成果を達成できる可能性はないかと考えたのです。
自分でも不完全と思うこのアイデアに対して、私のチームはフィードバックを提供してくれ、非常に多くの課題が明らかになりました。
- ライブパッチモジュールの削除をどのように処理するか。削除時に元のIDTが復元されたとしても、削除しようとしているエントリーコードの置換をCPUによって妨害することはできません。
- アドレスマッピングの一貫性とセマンティクスの変更の間の対立。
- パフォーマンスに対する影響を許容範囲内に保つには、ライブシステムでCPUのプロセスコンテキストID (PCID)機能を有効にする必要があります。同様に、グローバルページ(PGE)をオフにする必要があります。
それにも関わらず、私のチームは、この冒険に飛び込んでどこまで行けるか試してみるよう勇気づけてくれました。この時点では、このパッチは本番リリースを目指すものではありませんでした。本番デプロイメントには、結果があまりにも複雑で、多方面に影響を与えることが理由です。
この続きは、「パート2:仮想アドレスマッピング、Meltdown脆弱性、そしてkGraft自体へのパッチ」をお読みください。
Related Articles
9月 05th, 2024
最も複雑な環境に高度な可視性を提供するRancher Prime Observabilityのご紹介
12月 02nd, 2024
SUSE認定の仮想化向けストレージ – シームレスな統合と信頼性を実現するエンタープライズ向けソリューション
7月 31st, 2024
RKEが2025年7月にサポート終了 – RKE2またはK3Sへの移行について
6月 21st, 2024
No comments yet