How SAPHanaSR helps to automate SAP HANA System Replication with SLES for SAP Applications
SAP HANA System Replication on SLES for SAP Applications
If you would like to know how to implement the solution including SUSE Linux Enterprise for SAP Applications, please read our setup guide available at: https://documentation.suse.com/sbp/sap/
What is this SAPHanaSR solution about?
The new SAPHanaSR solution created by SUSE is to automate the takeover in SAP HANA system replication setups.
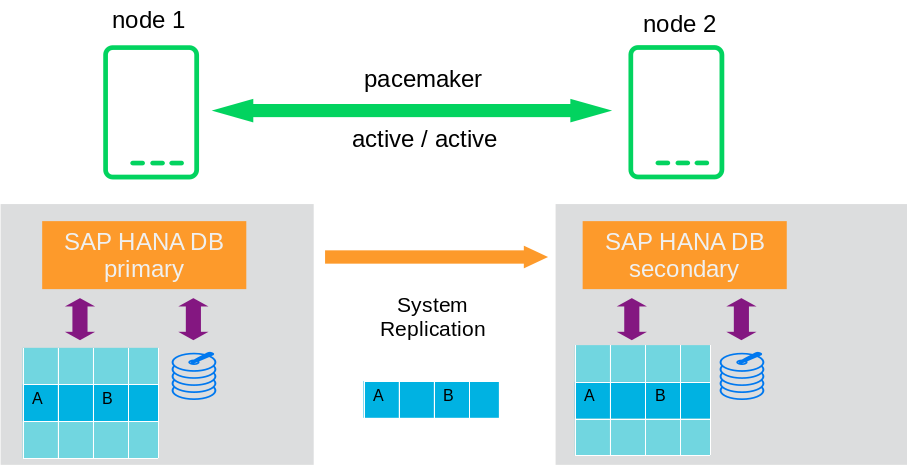
SAP HANA performance optimized scenario and SUSE cluster
The basic idea is that only synchronizing the data to the second SAP HANA instance is not enough, as this only solves the problem of having the data shipped to a second instance. To increase the availability you need a cluster solution, which controls the takeover of the second instance as well as providing the service address for the client access to the database.
| The first picture shows a SAP HANA “PR1” in system replication setup. The left node has the primary SAP HANA instance which means that this one is the instance clients should access for read/write actions. | 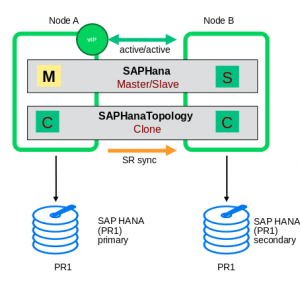 |
| The second picture shows what happens first, when either the node1 or the instance on that node is failing. The setup has now a “broken” SAP HANA primary and of course also the synchronization to the second node is stopped. | 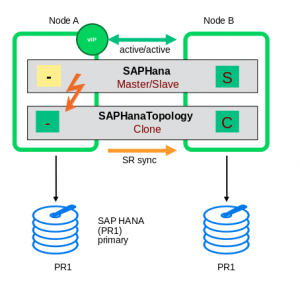 |
| Picture 3 shows the cluster’s first reaction: The secondary will be switched into a primary and in addition this new primary will be configured as new source of the system replication. Because of node1 or its’ is SAP HANA instance is still down, the synchronization is not in “active” mode. | 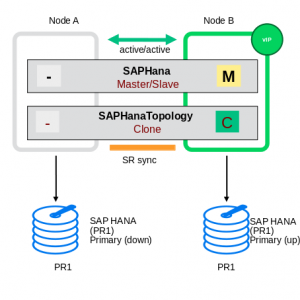 |
| Picture 4 shows the situation, when node1 (or it’s) SAP HANA instance is back. Depending on the resource parameters the cluster registers the former primary to be the new secondary and the system replication begins to work. | 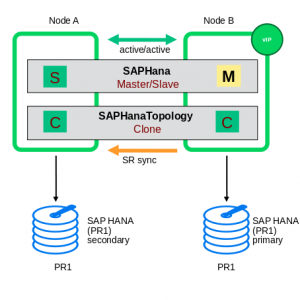 |
If you do not like the cluster to proceed an automated registration of the former primary, you could change the resource parameters and the cluster will keep the “broken”/former primary in shutdown status. This could make sense, if administrators first like to figure out what happened at this instance in detail or for other operating aspects.
When the automated registration is switched off, the administrator could register the former primary at any time. The cluster resource agent will detect this new status during the following monitor action.
Read more about current limitations, recommendations and a list of setup-steps in my next blog article.
No comments yet