Confidential Cloud: Introduction to Confidential Computing
 Introduction
Introduction
In this blog series, we will embark on a journey into the realm of Confidential Computing, CoCo for friends. Our goal? To help you gain a better understanding of it.
What is confidential computing about?
If we seek a definition for ‘Confidential Computing,’ Wikipedia provides us with the following: “a security and privacy-enhancing computational technique focused on protecting data in use.”, the key concept to emphasize here is ‘data in use‘.
Data is now considered the new gold, and Confidential Computing (CoCo) is all about protecting this valuable asset while it’s in use or “on the run”. The last thing anyone wants is their data being snooped on. Though long-established mechanisms exist to secure your data by encrypting it during transfer or while in cold storage, there’s limited action we can take, from a purely software standpoint, to encrypt it during processing by the CPU and storage in memory. This is where CoCo becomes instrumental. By integrating hardware and software solutions, we can safeguard the data, ensuring it cannot be tampered with or accessed by unauthorized parties.
What problems are confidential computing trying to solve?
The previous section already gave us an idea, but let’s dive into some real use cases.
With widespread use of cloud services, many companies are concerned about third parties gaining unauthorized access to their data. The “old” saying that “the cloud is just someone else’s computer” still holds true. Technically, employees working at cloud providers can access client data. While cloud providers strive to prevent such occurrences, the potential for rogue employees gaining access to customer data remains, particularly in virtualized and containerized environments. Here, administrators with the right privileges can access the memory associated with the VM or container. In simple terms the question here is:
- Do you trust the employees of your cloud provider?
Confidential computing shifts the focal point of your trust from cloud provider employees to the encryption algorithm and the hardware vendor, so the question becomes:
- Do you trust your encryption algorithm and hardware, or would you prefer to trust a random cloud provider’s employees?
But the scope of Confidential Computing extends beyond just cloud providers. It also aims to eliminate scenarios where hardware containing your data, if lost or stolen, could allow criminals to access that data.
Imagine if someone with malicious intent manages to gain physical access to your data center where your computers are running. While this may seem improbable, if there’s sufficient motivation to acquire that data, various methods exist to extract encryption keys stored in memory, which could then be used to decrypt your communications or encrypted storage.
While there are other scenarios, the main goal of Confidential Computing is to prevent the theft or manipulation of your data while it’s in use.
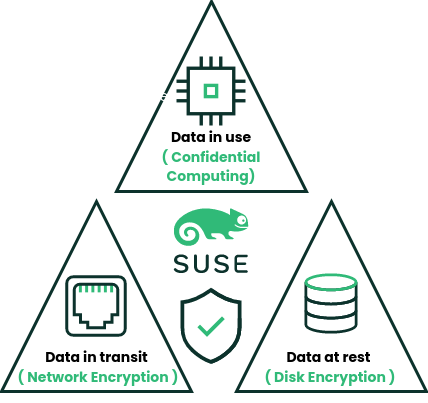
How can we protect our data?
We have different mechanisms available:
-
Data at rest -> Disk encryption
Nowadays it is very common to encrypt the storage devices, supported in the Linux kernel since approximately 2002 ( Kernel development [LWN,net] ) , we can even configure a client-server infrastructure to manage disk encryption for our systems, eliminating the need to manually input keys every time a server reboots.
For practical guidance on how to accomplish this please visit our documentation
-
Data in transit-> Network encryption
This practice has also become commonplace today; it’s rare to find anyone still using telnet or http. Instead, most strive to establish encrypted communications between applications, typically employing Public Key Infrastructure ( PKI )
Even though there’s hardware that facilitates the task and reduces the performance impact, these measures are generally implemented at the OS and application levels.
For practical information about OS related security measures, please visit our SLES Security and Hardening Guide.
-
Data in use-> Memory encryption
This is the most complicated part of all, because it requires hardware to be truly useful, there’s little sense in encrypting memory with the OS if the key is going to be stored in an unencrypted portion of the memory.
Here, by integrating both hardware and software, we can ensure our data has not been accessed or tampered with by implementing an attestation process. Here is a link to our documentation outlining one method, but stay tuned as we continue to explain this throughout the series.
How does it work?
An encryption engine is situated between the memory access module within the CPU and the physical memory outside the CPU. This encryption engine utilizes AES encryption to secure the data flowing between the CPU and the physical RAM.
Any plaintext data exists solely on the CPU itself.

This hardware feature also provides a method to confirm that the memory utilized by our virtual machines, for instance, hasn’t been tampered with and remains inaccessible to the hypervisor.
We will go into more details during the subsequent parts of this blog series.
Conclusion
Having gained a fundamental understanding of Confidential Computing and its objectives, we are better equipped to explore this topic in greater depth in upcoming parts of the blog series.
For more information about our products and services, please don’t hesitate to contact us or meet us at the SUSE stand in the KubeCon & CloudNativeCon North America 2023, Chicago November 6-9 where you will be able to see some cool demos about our security solutions and grab some swag.
👉 Learn more about SUSE security solutions.
Related Articles
Oct 30th, 2025