SAPHanaSR-ScaleOut: Automating SAP HANA System Replication for Scale-Out Installations with SLES for SAP Applications
This blog article is part of a blog series, explaining the SAPHanaSR Scale-Out solution. This article explains the SAPHanaSR technology and HANA System Replication at a more detailed level. Read also an overview around SAP HanaSR Scale-Out and HANA System Replication written by team colleague Markus Gürtler.
SAP HANA System Replication on SLES for SAP Applications
You might already have read my blog post about SAPHanaSR. In that blog I described the principles of a single-node SAP HANA in system replication with a second single-node SAP HANA. The scenario is also called “Scale-Up” because you can scale a growing SAP HANA database by adding resources to such a single node.
This new blog is now about a big next step which brings us to the “Scale-Out” Architecture, where a multiple-node SAP HANA is syncing with a second multiple-node SAP HANA. In “Scale-Out” installations you can scale a growing SAP HANA database either by adding new nodes to the landscape or by adding resources to all existing nodes.
This blog is intended to give you an overview about running SAP HANA Scale-Out system replication with SUSE Linx Enterprise Server for SAP Applications.
Please also visit our best practices landing page. This landing page is used to publish a library of best practice guides around the thematic of high availability for mission critical SAP applications.
What is SAPHanaSR-ScaleOut about?
Overview
The new SAPHanaSR-ScaleOut solution created by SUSE is to automate the takeover in SAP HANA system replication setups in multi-node, that means Scale-Out, installations.
The basic idea is that only synchronizing the data to the second SAP HANA instance is not enough, as this only solves the problem of having the data shipped to a second instance. To increase the availability you need a cluster solution, which controls the takeover of the second instance as well as providing the service address for the client access to the database.
The SAPHanaSR-ScaleOut package provides resource agents (RA) and tools for setting up and managing automation of SAP HANA system replication (SR) in scale-out setups. System replication will help to replicate the database data from one site to another site in order to compensate for database failures. With this mode of operation, internal SAP HANA high-availability (HA) mechanisms and the Linux cluster have to work together.

SAPHanaSR-ScaleOut-Cluster
An SAP HANA scale-out setup already is, to some degree, an HA cluster on its own. The HANA is able to replace failing nodes with standby nodes or to restart certain sub-systems on other nodes. As long as the HANA landscape status is not “ERROR” the Linux cluster will not act. The main purpose of the Linux cluster is to handle the take-over to the other site. Only if the HANA landscape status indicates that HANA can not recover from the failure and the replication is in sync, then Linux will act. As an exception, the Linux cluster will react if HANA moves the master nameserver role to another candidate. SAPHanaController is also able to restart former failed worker nodes as standby. In addition to the SAPHanaTopology RA, the SAPHanaSR-ScaleOut solution uses a “HA/DR providers” API provided by HANA to get informed about the current state of the system replication.
Note: To automate SAP HANA SR in scale-up setups, please use the package SAPHanaSR.
SAP HANA Node Roles
Don’t get confused about the terms “Master”, “Slave” or “Standby”. As we need to combine here two worlds both have used such terms in their own way. To help a bit reducing the possible confusion, we add prefixes like “SAP HANA…” or “Pacemaker…” to the terms to make it easier to identify them.
In a SAP HANA Scale-Out database system you have various roles. This section gives a high-level information about which roles are currently available and need to be handled by our automation solution.
SAP HANA Worker and Standby Nodes
A SAP HANA scale-out database consists of multiple nodes and SAP HANA instances.

Each worker node (W) has its own data partition. Standby nodes (S) do not have a data partition.
SAP HANA Master Name Server and Candidates
A SAP HANA scale-out database consists of several services such as master name server M.
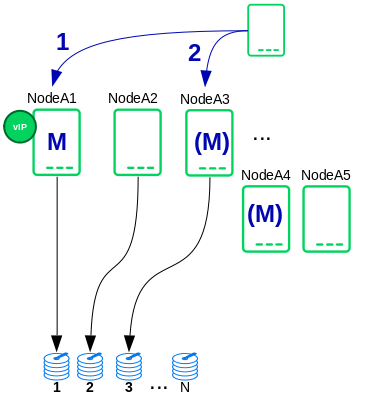
The active master name server takes all client connections and redirects the client to the proper worker node. It always has data partition 1. Master candidates (M) could be worker or standby nodes. Typically there are up to 3 nodes which could get active master name server.
Typical Use-Cases and Failure Scenarios
In order to illustrate the meaning of the above overview, some important situations are described below. This is not a complete description of all situations.
- Local start of standby node
The Linux cluster will react if HANA moves any worker node (including the master nameserver role) to another candidate. If the failed node or instance is available in the cluster and switched to HANA standby role, the Linux cluster will restart the SAP HANA local framework so this node could be used for future failovers. This is one exception from the general rule, that the Linux cluster does nothing as long as the HANA landscape status is not “ERROR”. - Prevention against dual-primary
A primary absolutely must never be started, if the cluster does not know anything about the other site. On initial cluster start, the cluster needs to detect a valid HANA system replication setup, including system replication status (SOK) and last primary timestamp (LPT). This is neccessary to ensure data integrity.The rational behind this is shown in the following scenario:- site_A is primary, site_B is secondary – they are in sync.
- site_A crashes (remember the HANA ist still marked primary).
- site_B does the take-over and runs now as new primary.
- DATA GETS CHANGED ON NODE2 BY PRODUCTION
- The admin also stops the cluster on site_B (we have two HANAs both
internally marked down and primary now). - What, if the admin would now restart the cluster on site_A?6.1 site_A would take its own CIB after waiting for the initial fencing
time for site_B.6.2 It would “see” its own (cold) primary and the fact that there was a
secondary.6.3 It would start the HANA from point of time of step 1.->2. (the crash),
so all data changed inbetween would be lost.This is why the Linux cluster needs to enforce a restart inhibit.
There are two options to get back both, SAP HANA SR and the Linux cluster, into a fully functional state:
a) the admin starts both nodes again
b) In the situation where the site_B is still down, the admin starts the
primary on site_A manually.The Linux cluster will follow this administrative decision. In both cases the administrator should register and start a secondary as soon as posible. This avoids a full log partition with consequence of a DATABASE STUCK.
- Automatic registration as secondary after site failure and takeover
The cluster can be configured to register a former primary database automatically as secondary. If this option is set, the resource agent will register a former primary database as secondary during cluster/resource start. - Site take-over not preferred over local re-start
SAPHanaSR-ScaleOut allows to configure, if you prefer to takeover to the secondary after the primary landscape fails. The alternative is to restart the primary landscape, if it fails and only to takeover when no local restart is possible anymore. This can be tuned by SAPHanaController(7) parameters.
The current implementation only allows to takeover in case the landscape status reports 1 (ERROR). The cluster will not takeover, when the SAP HANA still tries to repair a local failure. - Recovering from failure of master nameserver
If the master nameserver of an HANA database system fails, the HANA will start the nameserver on another node. Therefore usually up to two nodes are configured as additional nameserver candidates. At least one of them should be a standby node to optimize failover time. The Linux cluster will detect the change and move the IP address to the new active master nameserver.
Implementation
The two HANA database systems (primary and secondary site) are managed by the same single Linux cluster. The maximum number of nodes in that single Linux cluster is given by the Linux cluster limit. An odd number of nodes is needed to handle split-brain situations automatically in stretched clusters.
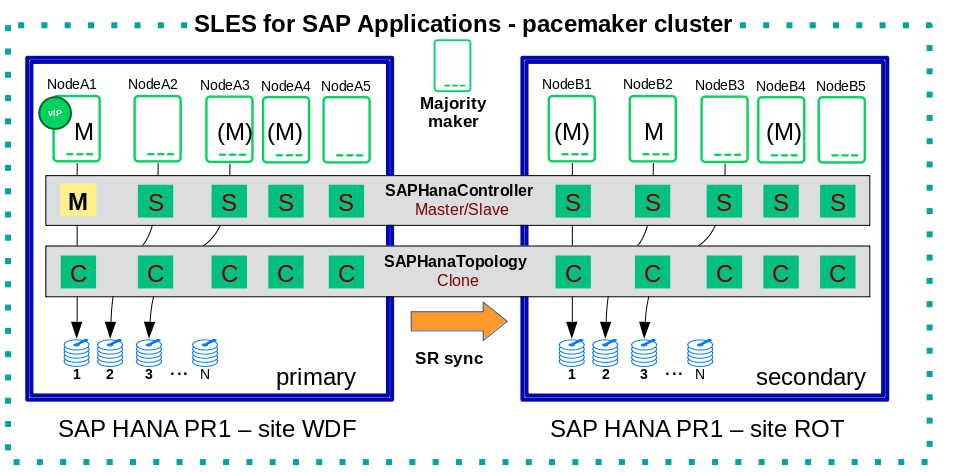
The HANA consists of two sites with same number of nodes each. There are no HANA nodes outside the Linux cluster. An additional Linux cluster node is used as majority maker for split-brain situations. This dedicated node does not need to have HANA installed and must not run any SAP HANA resources for the same SID.
There two resource agents running on each SAP HANA node. They are named SAPHanaController and SAPHanaTopology. In short words SAPHanaController does all actions on SAP HANA while SAPHanaTopology only analyzed the current status and shares it’s findings with SAPHanaController to allow optimized actions. SAPHanaController is designed as master/slave or multi-state resource. The Pacemaker Master (promoted clone) status will be assigned to the SAP HANA Active Master Name Server of the primary site. All other SAP HANA nodes are running with the Pacemaker Slave (demoted) resource status.
A common STONITH mechanism is set up for all nodes accross all the sites.
Since the IP address of the primary HANA database system is managed by the cluster, only that single IP address is needed.
Best Practice
- Use two independent corosync rings, at least one of them on bonded network. Resulting in at least three physical links. Unicast is preferred.
- Use Stonith Block Device (SBD), shared LUNs across all nodes on all (three) sites. Of course, together with hardware watchdog.
- Align all timeouts in the Linux cluster with the timeouts of the underlying storage and multipathing.
- Check the installation of OS and Linux cluster on all nodes before doing any functional tests.
- Carefully define, perform, and document tests for all scenarios that should be covered.
- Test HANA HA and SR features without Linux cluster before doing the overall cluster tests.
- Test basic Linux cluster features without HANA before doing the overall cluster tests.
- Be patient. For detecting the overall HANA status, the Linux cluster needs a certain amount of time, depending on the HANA and the configured intervalls and timeouts.
- Before doing anything, always check for the Linux cluster’s idle status, the HANA landscape status, and the HANA SR status.
Requirements
For the current version of the package SAPHanaSR-ScaleOut, the support is limited to the following scenarios and parameters:
- HANA scale-out cluster with system replication. The two HANA database systems (primary and secondary site) are managed by the same single Linux cluster. The maximum number of nodes in that single Linux cluster is given by the Linux cluster limit. An odd number of nodes is needed to handle split-brain situations automatically. A dedicated cluster node might be used as majority maker.
- Technical users and groups such as sidadm are defined locally in the Linux system.
- Strict time synchronization between the cluster nodes, f.e. NTP.
- For scale-out there is no other SAP HANA system (like QA) on the replicating node which needs to be stopped during take-over.
- Only one system replication for the SAP HANA database.
- Both SAP HANA database systems have the same SAP Identifier (SID) and Instance Number.
- Besides SAP HANA you need SAP hostagent to be installed and started on your system.
- Automated start of SAP HANA database systems during system boot must be switched off.
- For scale-out, the current resource agent supports SAP HANA in system replication beginning with HANA version 1.0 SPS 11 patch level 112.02. Older versions do not provide the srHook method srConnectionChanged().
- For scale-out, if the shared storage is implemented with another cluster, that one does not interfere with the Linux cluster. All three clusters (HANA, storage, Linux) have to be aligned.
Further Documentation
Web Sites
https://www.suse.com/products/sles-for-sap/resource-library/sap-best-practices.html,
https://www.suse.com/releasenotes/,
https://www.susecon.com/doc/2015/sessions/TUT19921.pdf,
https://www.susecon.com/doc/2016/sessions/TUT90846.pdf,
http://scn.sap.com/community/hana-in-memory/blog/2014/04/04/fail-safe-operation-of-sap-hana-suse-extends-its-high-availability-solution,
http://scn.sap.com/docs/DOC-60334,
http://scn.sap.com/community/hana-in-memory/blog/2015/12/14/sap-hana-sps-11-whats-new-ha-and-dr–by-the-sap-hana-academy
Man Pages
ocf_suse_SAPHanaTopology(7), ocf_suse_SAPHanaController(7), ocf_heartbeat_IPaddr2(7), SAPHanaSR-monitor(8), SAPHanaSR-showAttr(8), SAPHanaSR.py(7), ntp.conf(5), stonith(8), sbd(8), stonith_sbd(7), crm(8), corosync.conf(5), crm_no_quorum_policy(7), cs_precheck_for_hana(8), cs_add_watchdog_to_initrd(8)
Related Articles
Apr 30th, 2026
No comments yet