CPU Isolation – Full dynticks internals – by SUSE Labs (part 2)
This blog post is the second in a technical series by SUSE Labs team exploring Kernel CPU Isolation along with one of its core components: Full Dynticks (or Nohz Full). Here is the list of the articles for the series so far :
- CPU Isolation – Introduction
- CPU Isolation – Full dynticks internals
- CPU Isolation – Nohz_full
- CPU Isolation – Housekeeping and tradeoffs
- CPU Isolation – A practical example
- CPU Isolation – Nohz_full troubleshooting: broken TSC/clocksource

We have just introduced the linux kernel timer tick, the role it plays within kernel internal state and service maintainance. Users of jitter-sensitive workloads may want to get rid of the stolen CPU cycles and CPU-cache trashing resulting from this high rate event.
However stopping the timer tick is not easy because many kernel components rely on a periodic event: timers, timekeeping and scheduler being the bulk of it. One exception though, when a CPU is idle, there is no need for such a 100~1000 Hz heartbeat. Indeed when a CPU doesn’t have any work to do, there is no task scheduler to maintain, no timer queued and no timekeeping user.
It’s therefore fairly natural that power saving became the first successful incentive to conditionally break the periodic tick because its aim specifically applied on idleness optimization. CONFIG_NO_HZ_IDLE then brought the base machinery to stop the periodic tick and implemented it for the idle case. This big footstep paved the way toward meeting jitter-sensitive workloads requirements, providing with a dynamic tick infrastructure. What remained was to extend that feature so that the tick could be stopped even when the CPU is busy. Yet the state of the art wasn’t nearly as close to the goal as one would expect. It took several years to solve each of the items described in the next section.
Alternatives to tick services
As stated before, the tick is needed by several subsystems that require either timed oneshot events (timer callbacks) or periodic events (scheduler, timekeeping, RCU, etc…). So if we want to stop the tick when the CPU runs actual tasks, we can’t ignore those requested events. We have to service them using alternatives or in the worst case restrict our services. Namely for each of these subsystem’s dependencies to the periodic tick we have to choose over what is possible and relevant among the following:
1. Affine to another CPU
Some work happen to execute on the current CPU tick but it could execute on another CPU without any problem. This is the case for unbound timers, ie: those that are not pinned to any CPU. Indirectly this also applies to unbound delayed workqueues as they rely on unbound timers. These timers are easily affined elsewhere, at the cost of some more overhead for the CPUs that will run these unbound works.
2. Offload to another CPU
Some tick work related to the current CPU is not initially designed to be executed on another CPU but we can manage to do it, usually at some cost. This is the case for RCU callbacks processing and regular scheduler tick.
2.1 RCU callbacks processing
RCU is a lockless synchronization mechanism that lets a writer execute a callback once a given update is guaranteed to be visible by all CPUs. Those callbacks are usually executed locally by the CPU that queued them, either from softirq context or from a pinned kernel thread named “rcuc”. Tracking and executing these callbacks requires the tick to poll on their queue and internal state.
To solve this, a feature named RCU NOCB, enabled with CONFIG_RCU_NOCB_CPU=y, allows to offload this whole work from the tick to a set of unbound kthreads named “rcuog, rcuop or rcuos”.
This of course brings specific overhead for the CPUs that run the rcuo[gps] kthreads and locking contention.
2.2 Scheduler tick
The scheduler needs to keep gathering many statistics about the local and global load of tasks in order to maintain its internal state up to date. For quite a while there was a residual 1 Hz tick on busy CPUs that entered in full nohz mode. Eventually those residual 1 Hz ticks have been offloaded to unbound workqueues.
This also brings more overhead for the CPUs that run these workqueues.
3. Replace a polling event with a context change event
The timer tick deduces informations from the context it has interrupted and from its frequency.
This is the ground of two important components that are “cputime accounting” and “RCU quiescent states reporting”. In order to handle these features without the tick, we need to deduce these informations from context changes and timestamps (usually at some cost). This may read very abstract so better look at these more in practice.
3.1 Cputime accounting
When one checks a procfs stat file for a given pid (/proc/$PID/stat), the cputime statistics can be retrieved for several contexts such as the time spent by the thread in user space, kernel space, guest, etc…
These numbers are maintained by the scheduler cputime accounting. The tick fires and checks which context it has interrupted. If it has interrupted the user context, one jiffy (the time between two ticks) is accounted to user time. If it has interrupted the kernel context, the jiffy is accounted to kernel time. This behaviour is displayed in the figure below:
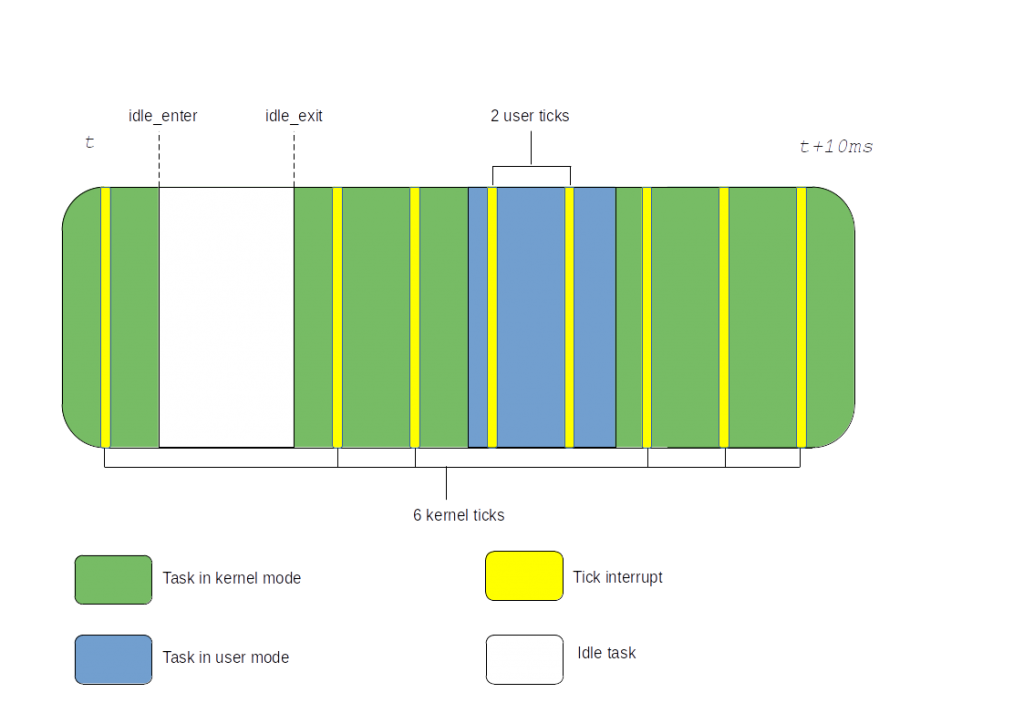 Figure 3: Dynticks-idle Cputime accounting
Figure 3: Dynticks-idle Cputime accounting
In the above example we are accounting 2 user ticks and 6 kernel ticks. For a 1000 Hz tick, a jiffy is equal to 1 millisecond. Hence 2 ms are recorded on user time and 6 ms on kernel time. The end result is always an approximation against the actual time spent in each context but it’s usually good enough. The higher the tick frequency, the more precise the cputime.
Now check the idle accounting. This one is different because there is no tick in idle so all we can do is to account the difference between the timestamps on idle exit and idle entry.
In order to be able to account user and kernel cputime when the tick is stopped while running a non-idle task, we must expand that idle accounting logic to user/kernel accounting. The new picture then looks like this:
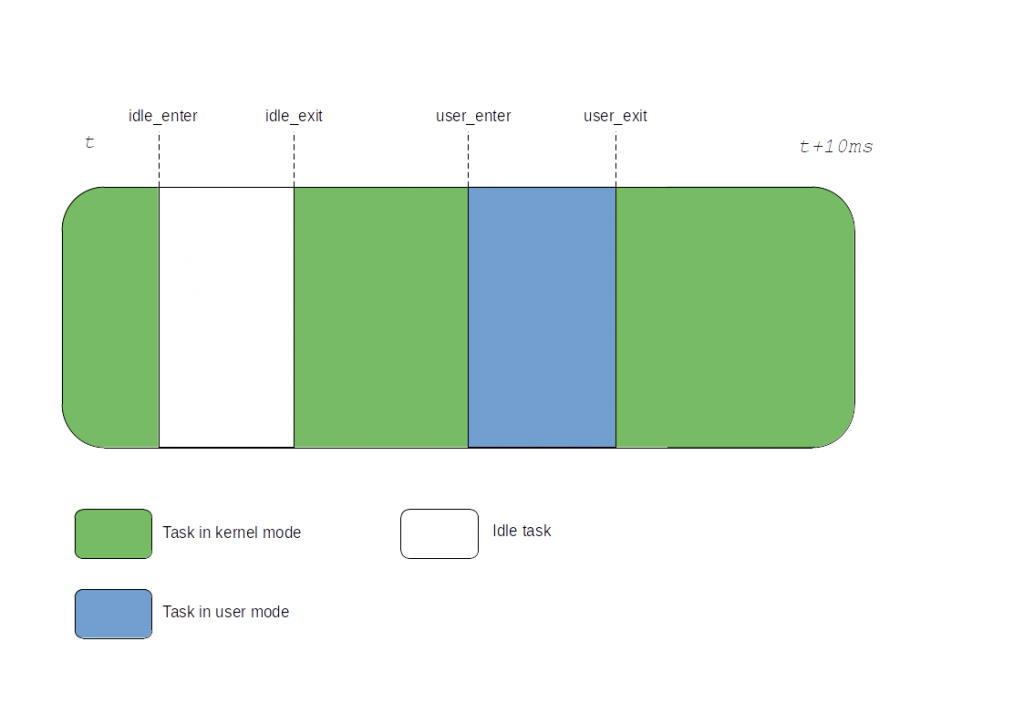 Figure 4: Full dynticks Cputime accounting
Figure 4: Full dynticks Cputime accounting
Here the kernel time can be retrieved by substracting the idle exit timestamp from the user enter one. And add anything that happened before idle_enter and after user_exit. The user time is the delta between user_enter and user_exit. It’s pretty simple and even more precise than the tick based accounting.
But then a question arise: why not use that solution all the time even when the tick runs?
Because it requires reading a precise but possibly slow to fetch hardware clock every time we cross a user/kernel boundary. And those round trips involving hardware clock fetch would happen often enough on generalist workloads to produce a performance penalty. Therefore this tickless accounting must be reserved to workloads that spare their entries to the kernel.
3.2 RCU quiescent states reporting
When an RCU writer issues an update and queues a callback to execute, it must wait for all CPUs to report a new “RCU quiescent state”. This means that a CPU has gone through code that wasn’t part of a protected RCU reader, which instead is called an “RCU read side critical section”.
In practice, any code between rcu_read_lock() and rcu_read_unlock() (or any non-preemptible code) is an “RCU read side critical section”. Everything else is an “RCU quiescent state”.
In order to chase quiescent states, RCU relies on the tick and checks which context it has interrupted. If the tick has interrupted code that wasn’t inside an rcu_read_lock()/rcu_read_unlock() pair protected section, it reports a quiescent state. If the tick has interrupted user space, it is also considered a quiescent state since user space can’t use the kernel RCU susbsystem.
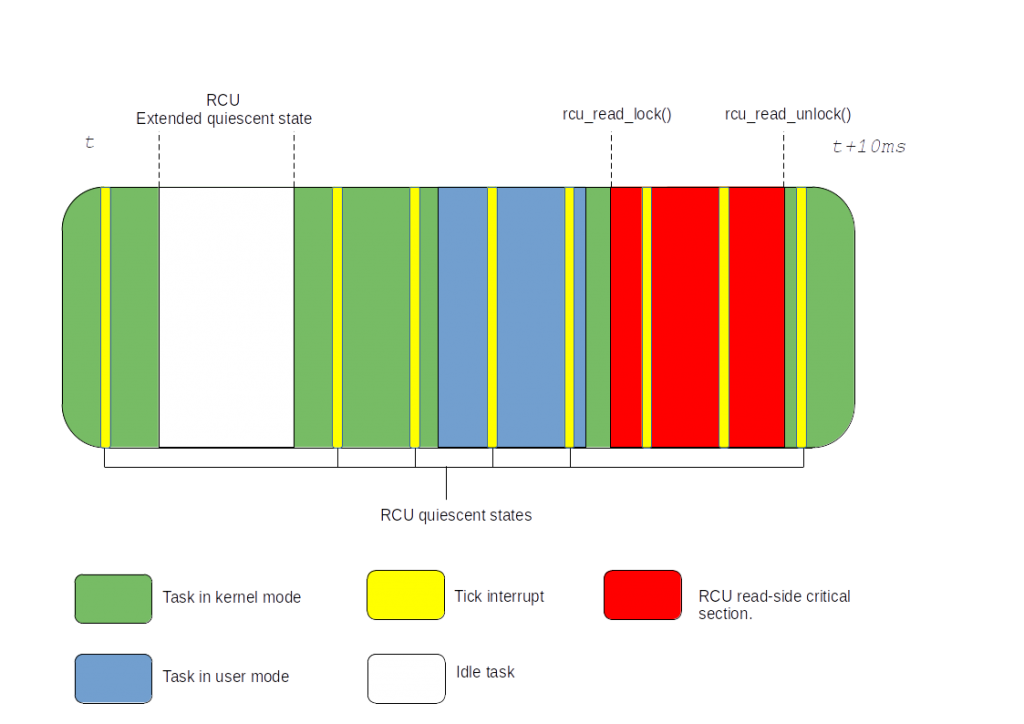 Figure 5: Dynticks-idle RCU quiescent state reporting
Figure 5: Dynticks-idle RCU quiescent state reporting
The figure above also illustrate how the tick-deprived idle task again benefits from a special treatment. Instead of actively reporting quiescent states, the idle CPU reports it passively with entering into an “RCU extended quiescent state”. It increments an atomic variable with a full memory barrier on idle entry and exit.
Then RCU, waiting for all CPUs to report quiescent states, eventually ends up scanning the non responding ones for extended quiescent states and report their quiescent state on their behalf.
This model works because we know that idle context doesn’t use RCU. And since we know that user space has the same property, this passive reporting scheme can then be expanded to it when the tick is stopped while running a non-idle task:
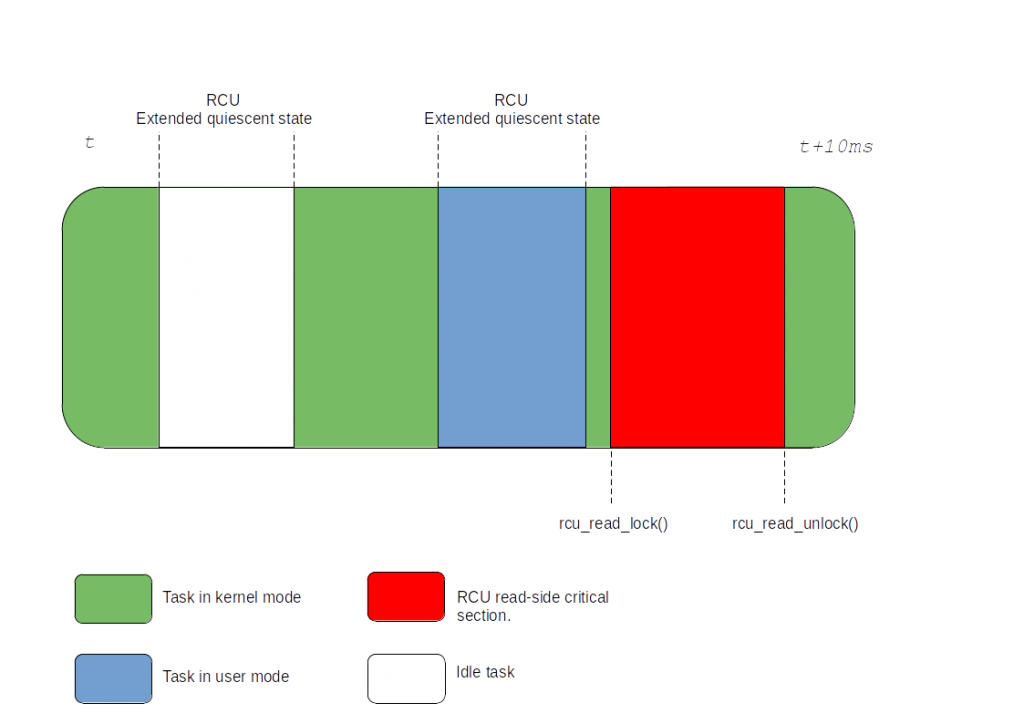 Figure 6: Full-dynticks RCU quiescent state reporting
Figure 6: Full-dynticks RCU quiescent state reporting
Since the CPU seldom spend much time in the kernel, the above proposal stands to replace the tick based quiescent state reports. RCU extended quiescent states either happen with short delays in-between or they stick for a long time.
Again a question arises, similar to the one on cputime accounting: why not adopting this model even when the tick runs?
Because that would inflict a costly atomic operation with a full memory barrier on every user/kernel round trip. Also the duty to report quiescent states eventually falls to other CPUs so one must be aware of the exported cost that implies.
4. Keep the tick alive if no alternatives
Some situations simply can’t be solved without a periodic event, or at least a frequent one. This is the case for scheduler task preemption for example. In order to maintain local fairness, the scheduler must be able to share the CPU between multiple tasks and periodically check if preemption is needed. Hence running a single task on a CPU is a requirement to stop the tick further the idle context. Other subsystems may also request the periodic tick to keep running on some situations: posix cpu timers, perf events, etc… We’ll explore those details further.
As you can see, stopping the tick completely while running an actual task is possible, but users must be ready for some tradeoffs. A lot of pitfalls wait in the corner and we’ll explain them more in practice in the next posts.
Related Articles
Feb 17th, 2026
No comments yet