CPU Isolation – Housekeeping and tradeoffs – by SUSE Labs (part 4)
This blog post is the fourth in a technical series by SUSE Labs team exploring Kernel CPU Isolation along with one of its core components: Full Dynticks (or Nohz Full). Here is the list of the articles for the series so far :
- CPU Isolation – Introduction
- CPU Isolation – Full dynticks internals
- CPU Isolation – Nohz_full
- CPU Isolation – Housekeeping and tradeoffs
- CPU Isolation – A practical example
- CPU Isolation – Nohz_full troubleshooting: broken TSC/clocksource

CPU isolation and nohz_full users need to be aware of a base principle in this field: the noise is seldom just removed, it is rather relocated instead.
Housekeeping
As we briefly explained previously, housekeeping is the periodic driven or event driven ground work that the kernel needs to do in order to maintain its internal state and services, such as updating internal statistics for the scheduler, or timekeeping.
On normal configurations, every CPU get its housekeeping duty share. On the opposite, nohz_full configurations implicitly move away all the housekeeping work outside the nohz_full set.
This means that if you have 8 CPUs and you isolate CPUs 1,2,3,4,5,6,7:
nohz_full=1-7
Then CPU 0 will handle the housekeeping workload alone. These duties involve:
- Unbound timer callbacks execution.
- Unbound workqueues execution.
- Unbound kthreads execution
- Timekeeping updates (jiffies and gettimeofday())
- RCU grace periods tracking
- RCU callbacks execution on behalf of isolated CPUs
- 1Hz residual offloaded timer ticks on behalf of isolated CPUs
- Depending on your extended setting:
- Hardware IRQs that could be affine
- User tasks others than the isolated workload
Although these items can usually be covered by a single CPU on behalf of 7 others, this layout can’t tend to infinity. As the number of CPUs grows, as the memory and caches get further partitioned, the housekeeping duty may need to be shared. It is usually admitted that having one housekeeper per NUMA node is a good start. As depicted within the following configuration:
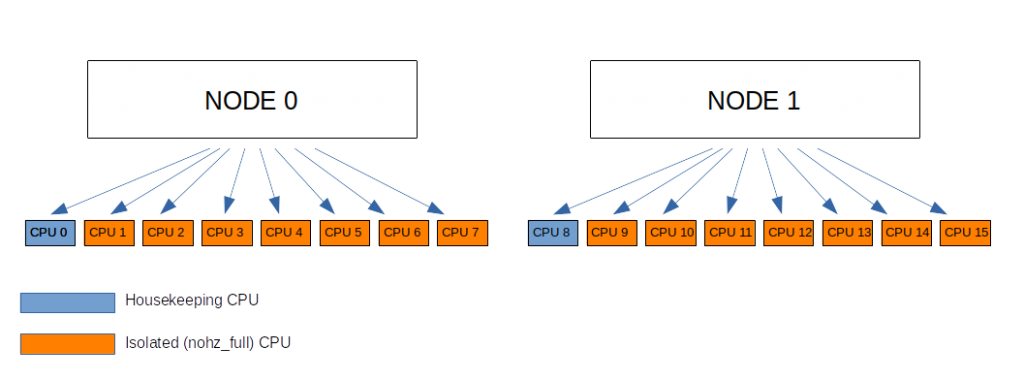
With CPUs 0 to 7 belonging to Node 0 and CPUs 8 to 15 belonging to Node 1, a default setting proposal would look like:
nohz_full=1-7,9-15
During the testing phase, it is recommended to check and monitor the activity of the housekeepers through tools like top/htop in order to make sure they are not overloaded. For example if the above setting displays 100% load on CPU 0 or CPU 8, then it may be worth adding more housekeeping CPUs, although such situation is more likely to be met within larger nodes.
It’s also important to note that trips to the kernel, such as syscalls or faults for example, may generate more housekeeping activity and result in more load for those CPUs in charge. It’s usually not advised to request kernel services too often anyway from an isolated CPU, as we’ll discover in the next chapter.
In any case, the kernel has housekeeping work to handle and it can’t be ignored. If all CPUs are passed to the “nohz_full=” kernel parameter, CPU 0 will be arbitrarily cleared out of the isolated set and assigned the housekeeping duty alone with the following message:
NO_HZ: Clearing 0 from nohz_full range for timekeeping
Therefore, be aware that the jitter-free power you gain on your set of isolated CPUs comes at the expense of more work for the other CPUs and that at the very least one CPU needs to be sacrificed for this work.
This condition isn’t fixed in stone though. We could arrange in the longer term for running all CPUs in isolated mode if timekeeping gets updated upon kernel entry and the scheduler is enhanced to support tasks running very long slices in userspace without the need for remote ticks to keep the stats up to date. We are not there yet though.
Kernel entry/exit overhead
The full dynticks mode adds significant overhead on kernel entry and exit. Those are the result of:
- Syscalls
- Exceptions (page faults, traps, …)
- IRQs
This overhead is first due to RCU tracking and ordering. That job is normally covered by the periodic timer tick. Now as we are getting rid of it, the last resort is to account trips through kernel boundaries using costly fully ordered atomic operations.
The second part of that overhead results from cputime accounting. Again the kernel has to account the time spent by the task both in kernel and user spaces using probes on kernel boundaries since the periodic tick isn’t there anymore to do the job. Although cputime accounting uses weaker ordering than RCU tracking does, it’s still some processing that adds up to the general overhead.
IRQs can be affine to housekeeping as we saw previously. Pages faults can be prevented using mlock(). Then its up to the user to mitigate the use of syscalls, which leads us to this hard rule: full dynticks isn’t suitable for kernel based I/O bound workloads. Instead it should be reserved for either:
- CPU bound workloads. Computation involving a lot of CPU processing and fewest kernel based I/O (those that rely on kernel drivers handled with syscalls and interrupts).
- I/O bound workloads that don’t involve the kernel, which means I/O’s based on userspace drivers such as DPDK for example.
Conclusion
CPU isolation and full dynticks can bring significant wins on some specific workloads but be aware that it isn’t suitable on many situations. In particular you must be aware of these two highlights:
- You’ll need to sacrifice at least one CPU off your isolated set in order to handle kernel boring internal work.
- Full dynticks is only eligible for CPU bound workloads or userspace drivers based I/O’s.
In the next article we’ll finally test this feature in practice and show how to chase and debug the remaining noise.