We did it again – Our HA solution is SAP Certified
 End of January we have achieved a new mile stone for our SLES for SAP Applications cluster solutions. We passed the SAP certification named “SAP S/4-HA-CLU 1.0” as the first cluster vendor. We have selected SLES for SAP Applications 15 as platform for the certification. However you could also implement the cluster with SLES for SAP Applications 12 SP4.
End of January we have achieved a new mile stone for our SLES for SAP Applications cluster solutions. We passed the SAP certification named “SAP S/4-HA-CLU 1.0” as the first cluster vendor. We have selected SLES for SAP Applications 15 as platform for the certification. However you could also implement the cluster with SLES for SAP Applications 12 SP4.
The difference between the certification for SAP S/4 HANA and the certification for SAP NetWeaver is that beginning with version ABAP platform 1809 SAP has changed to the new Enqueue Standalone Architecture (ENSA2).
You can find SUSE in the SAP Certified Solutions Directory.
New SAP Certification Criteria
SAP has introduced some new certification criteria and goals:
- The architecture must be available in a two node (n=2) and a multiple node (n>2) cluster setup.
- The solution must be able to interact with the new ASCS and ERS instances including the new enqueue server and the new enqueue replication server.
- The cluster must be able to migrate the ASCS to an optimal cluster node. For n>2 cluster nodes this should never be the ERS node, because then the replication would not be “spanned-up” over different nodes. The admin could trigger the migration by using the new sapcontrol function HAFailoverToNode.
- The integration should provide a interface to set the maintenance mode of single instances using the new sapcontrol command HASetMaintenanceMode and HACheckMaintenenceMode.
What is the difference between ENSA1 and ENSA2?
We already explained that beginning from ABAP platform 1809 SAP has changed from the former enqueue server (ENSA1) to the new ENSA2 by default. But what is the difference and how does that change effect the cluster?
First of all let us have a look at the difference in the enqueue recovery after an ASCS failure (node or software):
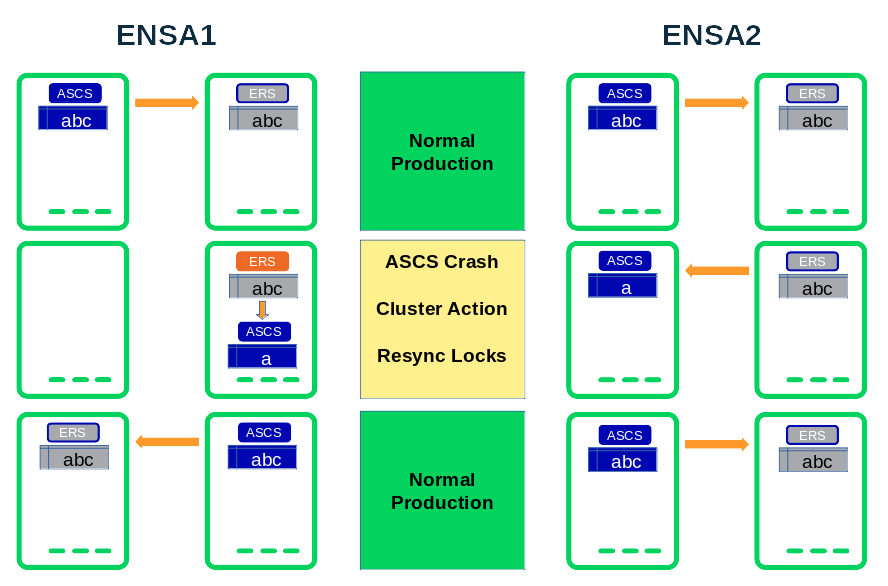
ENSA1 vs ENSA2 Lock Recovery
The enqueue recovery process in ENSA1 works on shared memory segments. This implies that the cluster needs to migrate the ASCS instance exactly the node which has the synchronized lock table. So in ENSA1 the lock table recovered works by “mounting” the shared memory of the ERS (replicator) SAP instance. This handling has some disadvantages: The SAP system could lose the locks, if the ASCS does not start on the correct host. Also the replication does not “spanned-up” over multiple nodes for at least a short time period. And the setup is not perfect clusters with more than 2 nodes.
The enqueue recovery process in ENSA2 works over the network. Once the ASCS (instance or node) fails, the cluster could restarted it either on the same or any other cluster node. The ASCS instance processes the lock recovery by fetching the locks from the ERS over a network connection. For clusters with more than two nodes (n>2) this gives an optimal high availability scenario. The cluster could select any node where the ERS is currently not running. After the locks recovery the replication is already running over different hosts.
Does the change from ENSA1 to ENSA2 effect the cluster?
Behind the scenes the SAP service got new names. While ENSA1 uses the service names msg_server, enserver and enrepserver, ENSA2 uses the service names msg_server, enq_server and enq_replicator. SUSE has developed an update for the SAPInstance resource agent which is already available in the maintenance channels for SLES for SAP Applications. This update could detect automatically ENSA1 and ENSA2 instances and could control and monitor both architectures without any need to make changes on the resource configuration.
We recommend to follow our brand new setup guide “SAP S/4 HANA – Enqueue Replication 2 High Availability Cluster – Setup Guide” available on our documentation web site https://www.suse.com/documentation/sles-for-sap-15/#bestpractice. You will get the above new features and your cluster will be compatible with the certification goals.
One of the main differences is that the new setup is now also supported for clusters with more than two nodes (n>2). We recommend to use an odd number of nodes to guarantee that always a majority of the cluster could proceed after cluster separations.
The second difference are the simplified cluster rules which does not longer differ between administrative actions and ASCS failures. The ASCS could always be first restarted locally and only as a second reaction moved to a different node. The following graphic illustrates the simplified resource groups as well as the different reactions expected from the cluster framework.

This is Fabian Herschel and Bernd Schubert blogging live from the SAP LinuxLab St. Leon-Rot, Germany. Please also read our other blogs about #TowardsZeroDowntime.
Related Articles
Jun 25th, 2025
Open Sovereign IT: How to Get Started
Aug 14th, 2025
Comments
Really Great! Congrats Fabian and Bernd!
Will this be available for SAP ERP ECC 6 with AWS Cloud platform
You need to differ products based on SAP NetWeaver and SAP S/4HANA. We have passed both certifications in the past already.
However SAP NetWeaver is still on ENSA1 while SAP S/4HANA is already in ENSA2. But that is not SUSEs decision. It’s SAP.
Very nice. Thanks
🙂