SAPHanaSR-ScaleOut for Multi-Target Architecture and Principles
SAP HANA supports multi-target system replications. But what does that mean “multi-target”? And how use it in a SUSE cluster? This blog introduces you to SAP HANA multi-target system replication and describes the major steps to get it running with the SUSE HA cluster. In addition it provides you a first view on how it looks from admin perspective. Technical details of the implementation will follow in another blog. Now let’s focus on the architecture and principles.

In the blog Scale-out large ERP systems we already described that ERP workloads are changing the architectural needs of cluster setups. It is very often not sufficient to replicate the data only in a so called metro-cluster. Customers now need to synchronize the data also to a disaster recovery (DR) location in addition to the fast system replication in their metro-clusters.
In this blog series you will learn how SUSE HA and SAPHanaSR-ScaleOut could cover the specific needs for ERP-style HANA scale-out systems.
The blog series consists of the following parts:
- Scale-out large ERP systems
- Scale-out multi-target (this article)
- Migrating to multi-target
- Scale-out maintenance examples (will follow soon)
- A reference part contains links to more detailed information, like specific requirements and configuration items. (link will follow soon)
This might differ from classical blog structures – we will see how it works for the given topic.
What was the Situation before we got Multi-Target System Replication?
At the beginning SAP HANA system replication only allowed one target per replication source. So a SAP HANA site “SiteA” was only able to sync with one other site. Let us call it “SiteB”, If you needed to add one more system replication site you registered the third site to “SiteB”, because “SiteA” was already occupied as system replication source. This topology was called chain or 3-tier system replication. Let us call the third site “DRSite”. It was already possible to have different operation modes between the sites, so the “DRSite” could be synced in async-mode while the local SAP HANA sides process a synchronous replication.
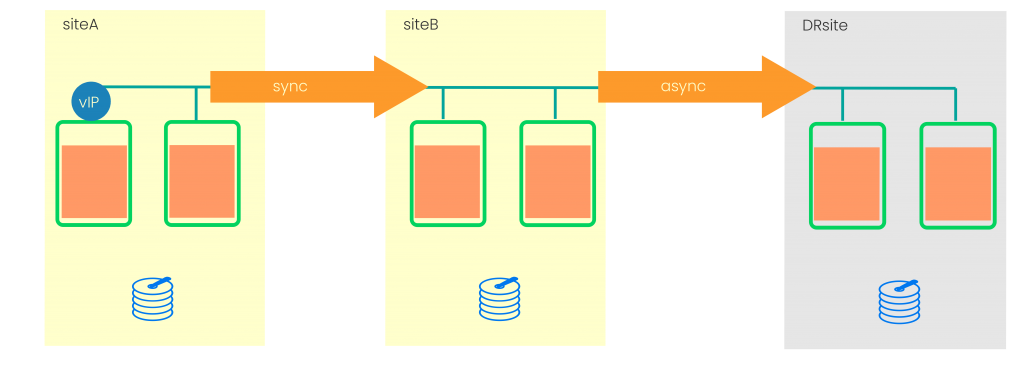
System Replication in Chain Topology
The chain topology was really a good first step but the limitation to one target was problematic when ever the admin (or a cluster) had the need to process a takeover to “SiteB”. In this case “SiteA” could not be registered directly to “SiteB” because it was already syncing to the “DRSite”. To get out of this and to register the former primary first the synchronization to the “DRSite” needs to be unregistered then you could register “SiteA” to the new primary to have the local system replication in place. Last you need to register the “DRSite” to sync from “SiteA”.
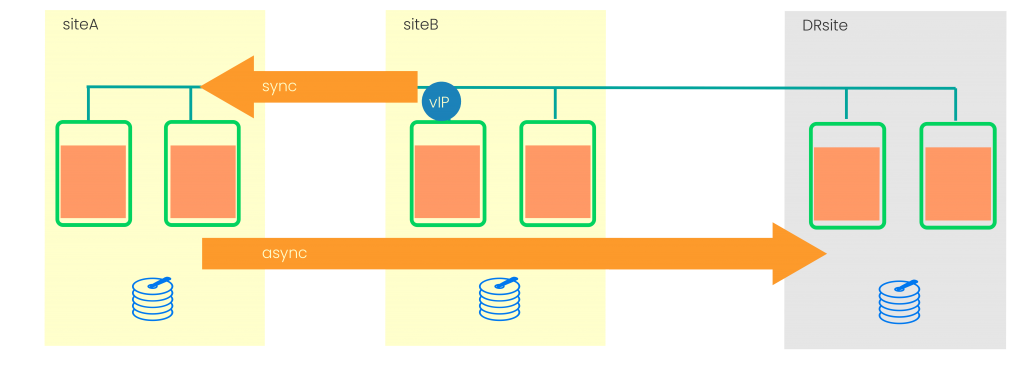
SAP HANA Chain Recovered
Finally after 4 steps needed to change the SAP HANA system replication topology we have a valid chain again. You see that is really a long and error prone. And that is why multi-target is a great improvement.
What’s new with Multi-Target System Replication?
With multi-target system replication each source could sync to multiple targets. And targets of the same source can use different operation modes. That means in example “sync” for a local replication and “async” for a synchronization to a DR site. This gives much more flexibility to process takeovers of the primary function.

You could even configure the secondaries to follow such takeovers and to automatically re-register themself triggered by the new primary. In our case “SiteA” syncs to “SiteB” and in parallel to that also to “DRsite”. If now “SiteA” fails and we process a takeover, the “DRsite” could already reconfigure to be synced from “SiteB”. So the DR synchronization is already recovered.

Now Adding the SUSE HA Cluster to Multi-Target
Now it’s time to add the SUSE HA cluster based on pacemaker and SAPHanaSR-ScaleOut to the multi target architecture. SAPHanaSR-ScaleOut does support the following multi-target architecture beginning with version 0.180.1. This package will appear in the maintenance channels in the future. But let us take time already to discuss about that new feature. The minimum SAP HANA version is 2.0 SPS3. This is the first SAP HANA version supporting HA/DR calls which could differ the failing/recovering site for system replication status changes. And of course the SUSE HA cluster needs to differ between errors on a local side from errors on the DR site.
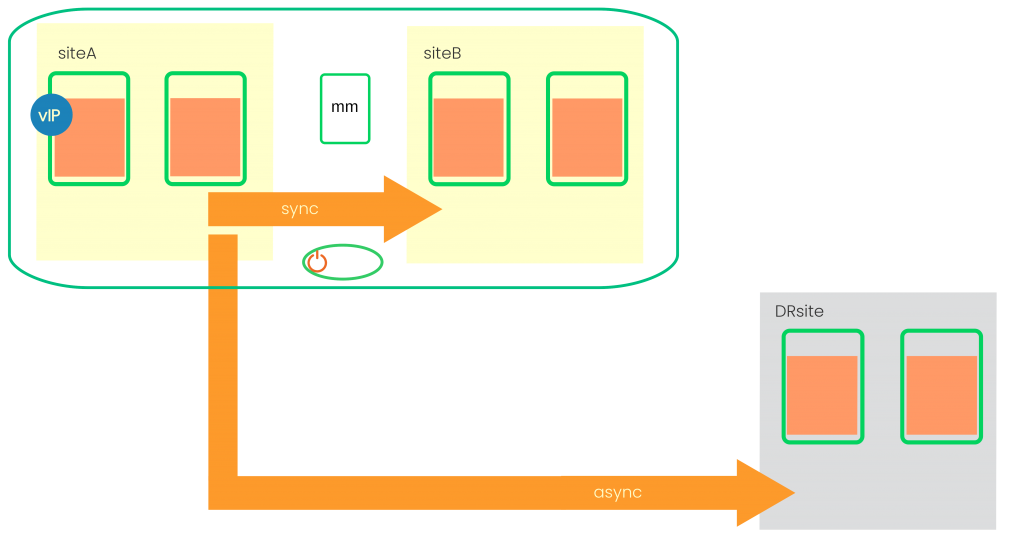
SUSE HA Cluster and Multi-Target Architecture
The picture “SUSE HA Cluster and Multi-Target Architecture” already shows the SUSE HA cluster which manages the system replication between “SiteA” and “SiteB”. These two sites are part of a so called local or metro-cluster. Network latency needs to be very low to allow SAP HANA to run with high performance and enabled system replication.
Explaining the Cluster Components
In the picture we see the SUSE HA cluster limited to those two SAP HANA sites. The SUSE HA cluster does not manage the DR site.
We see the majority maker (mm) as an additional cluster node. The majority maker should ideally reside on a separate site to allow error handling for complete site failures. In such a case SUSE HA cluster needs a clear majority to decide which side could keep the production. In our example we have 5 cluster nodes. Each SAP HANA site has 2 nodes plus the majority maker. If now one SAP HANA site gets separated in the network or completely lost, we have 2 nodes isolated or lost. 3 nodes are remaining, forming a functional cluster partition. The majority of the nodes is >= int(nodes/2)+1. This number is 3 in our example. And that’s why the majority maker can help the cluster to decide correctly which site to keep running and which site needs to release the resources.
As a third architecture component we see the STONITH fencing device. Host fencing enables the cluster to guarantee that lost nodes do not continue to run their resources while the cluster likes to perform a takeover. This provides improved data integrity. We recommend SBD diskless as the best matching fencing method. If your cloud provider does not support diskless SBD please follow their recommendation. Diskbased SBD is the second best option. It is also very stable. However you need 3 block devices accessible from all 3 cluster sites. Providing such block devices could be problematic in some public cloud environments.
Clients access SAP HANA via the virtual IP (vIP) address. The cluster places the IP address on the master nameserver of the SAP HANA primary site. The IP address follows the takeover of the primary role whenever the SUSE HA cluster performes a SAP HANA takeover to the other side. The global.ini option “register_secondaries_on_takeover = true” in section system_replication allows the secondaries to follow the takeover decision.
How the Cluster process an SAP HANA Primary Failure
 |
Normal operation
At the beginning both SAP HANA sites are running. The system replication is “in sync” and the primary also syncs to the DR site. Now we assume the primary SAP HANA site is dying. |
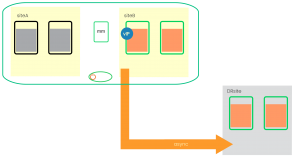 |
Cluster Takeover Primary to second site
The cluster detects the failed primary. The system replication status before the failure was still “in sync”. This allows the cluster to run an sr_takeover on the secondary to takeover the primary role. The cluster moves the virtual IP to the new running primary. The DR site re-registers triggered by the new primary and is following the new topology. Depending on your configuration the cluster now registers the former primary to get the new secondary. |
 |
Recovered System Replication Topology
The cluster detects the new role of the former primary. It starts the new secondary. The system replication starts and finally comes again to the “in sync” status. Finally the cluster sets the internal attributes to mark the system replication as OK again. |
The Major Steps to Implement the Cluster
This list describes the major steps. To keep it short it contains only the steps at a glance. The follow-up log will provide the details of the steps.
- SAP HANA is running on two or already three sites. The system replication is up-and-running.
- Install the SUSE HA cluster software package including SAP HANA Scale-Out with minimum version 0.180.1 on all cluster nodes including the majority maker.
- Set-Up the cluster basics and set the cluster to maintenance mode because we do not want the cluster to start parts of the resources while we are configuring the solution. As a result we have a minimum cluster running.
- Configure the cluster properties, resources and constraints. The result is that the cluster knows about the SAP HANA resources.
- Adapt sudoers permission on all nodes including the majority maker.
- Configure the HANA HA/DR hook script SAPHanaSrMultiTarget.py on both sites.
- Let SAP HANA load the HA/DR hook script on all sites. As a result we can see the ha_dr_ trace entries in the SAP HANA trace files.
- Set SUSE HA cluster to end the maintenance mode and to start control the SAP HANA sites and IP address. Now the cluster begins to manage and operate the SAP HANA sites.
- Check the cluster and run all needed cluster tests.
- Finally check if everything looks fine.
How does the Cluster looks like from Admin Perspective?
SAPHanaSR-ScaleOut contains the script SAPHanaSR-showAttr. Using this script it is easy to check which cluster attributes are available in the cluster: In the following example we are using “S1” and “S2” for the local SAP HANA sites and “S3” for the DR site. The cluster nodes are suse00 (majority maker), suse11 and suse12 on site S1. As well as suse21 and suse22 representing site S2. As you can see site S2 is currently the running primary.
Global cib-time prim sec sync_state ----------------------------------------------------- HA1 Mon Aug 9 12:28:40 2021 S2 S1 SOK Site lpt lss mns srHook srr -------------------------------------- S1 30 4 suse11 SOK S S2 1628503669 4 suse21 PRIM P S3 SOK Hosts clone_state gra node_state roles score site ------------------------------------------------------------------------ suse11 DEMOTED 2.0 online master1:master:worker:master 100 S1 suse12 DEMOTED 2.0 online slave:slave:worker:slave -12200 S1 suse21 PROMOTED 2.0 online master1:master:worker:master 150 S2 suse22 DEMOTED 2.0 online slave:slave:worker:slave -10000 S2 suse00 2.0 online
Where can I find further information?
Find more details on requirements, parameters and configuration options in the setup guide as well as in manual pages SAPHanaSR-ScaleOut(7), ocf_suse_SAPHanaController(7), SAPHanaSrMultiTarget.py(7) and SAPHanaSR-ScaleOut_basic_cluster(7).
Please have a look at the reference part of this blog series (link will follow soon).
What to take with?
- Multi-target system replication gives us much more flexibility.
- The cluster needs SAPHanaSR-ScaleOut version 0.180.1 or later to support multi-target replication.
- The SUSE HA cluster does not operate the DR site.
- SAP HANA 2.0 SPS03 is the first version providing attributes to differ system replication status changes per target site.
- The majority maker enables clear cluster partition majorities.
- Proper STONITH host fencing is a must for each supported SUSE HA cluster.
- SBD diskless and alternatively SBD diskbased are the preferred fencing methods.
Related Articles
Aug 07th, 2025