How to Optimize I/O Intensive Containers on Kubernetes
Understanding the Real-time Characteristics of Linux Containers
By Jay Huang
Highly threaded, I/O intensive Linux containers running on Kubernetes should be able to use the full extent of their CPU requests. But is this really possible? Understanding how the Linux operating system schedules tasks and allocates CPU time to tasks can help application developers optimize containers which are highly threaded and I/O intensive.
Introduction
Nowadays, data has influenced almost all aspects of life. If it isn’t already there, the technological landscape will soon be completely data centric. Data clouds provide a huge opportunity to expand the horizon of possible applications with almost infinite scalability. When the cloud is healthy, your services are healthy, too. However, how do you know the cloud is healthy, especially for your specific container performance? There could be dangerous consequences if the cloud lacks diagnostic capabilities that require high reliability for process fault diagnosis and real-time responses. When the cloud has been attacked, how fast can you defend your services in real-time?
The notion of real-time containers was conceived as the convergence of software container technologies, such as Linux Containers and/or Docker, and real-time operating systems. The idea was to allow critical containers, characterized by stringent timeliness and reliability requirements, to co-exist with traditional non real-time containers on the same hardware. But, is this really an easy and practical solution to deploy? Failure of such real-time containers to receive their required resources could seriously impact critical performance and possibly security metrics.
Requirements of Highly Threaded, I/O Intensive Linux Containers
As said earlier, “Highly threaded, I/O intensive Linux containers running on Kubernetes should be able to use the full extent of their CPU requests.” This means that in an ideal situation, these containers should receive the CPU time they require. This demands a higher priority to manipulate I/O requests, a real-time container profile, as well as a runtime environment to facilitate CPU requests. In this case, it also requires a highly cooperating real-time operating system.
To accomplish this, you first need a real-time scheduler in the host kernel. Second, you need to install a certain version of the container runtime engine which integrates with the OS kernel scheduler. Third, you need to be able to configure your “individual containers” explicitly with parameters such as special CPU requests.
The problem is that this type of solution is still not popular and widespread today. Below is a warning from the most popular runtime provider, “Docker.”
“Warning: CPU scheduling and prioritization are advanced kernel-level features. Most users do not need to change these values from their defaults. Setting these values incorrectly can cause your host system to become unstable or unusable”
To be able to fully complete such a system requires collaboration between the host providers and the runtime engine providers (e.g. docker, containerd, cri-o). Container developers also need to be involved with its development and testing to make sure it works and is stable. To date, this has not been possible because of the time intensive development and the coordination required between companies and industry groups.
We can’t wait for this to happen. Is there an interim solution? Let’s examine the “default” solution currently in the market to find out how far we can get in solving this problem.
Back to the Default, a “Completely Fair Scheduler”
At the very beginning, a container had no resource constraints and could use as much of a given resource as the host’s kernel scheduler would allow. This created a huge problem for other containers to be able to share CPU resources together. In Linux, the kernel needed a new CPU bandwidth control mechanism to solve this issue. This is what the new task scheduler, CFS, which is merged in Linux 2.6.23, provides. CFS stands for “Completely Fair Scheduler.” It provides:
- Maintains balance (fairness) in providing CPU time to tasks.
- When the time for tasks is out of balance, then those out-of-balance tasks should be given time to execute.
- To determine the balance, the amount of time provided to a given task is maintained in the virtual runtime (amount of time a task has been permitted access to the CPU).
- The smaller a task’s virtual runtime, the higher its need for the processor.
- The CFS also includes the concept of sleeper fairness to ensure that tasks that are not currently runnable receive a comparable share of the processor when they eventually need it.
- CFS doesn’t use priorities directly.
CFS maintains a time-ordered “RB Tree”, operations on the tree occur in O(log n) time, where all runnable tasks are sorted by the p->se.vruntime key. CFS picks the “leftmost” task from this tree and sticks to it. As the system progresses forwards, the executed tasks are put into the tree more and more to the right — slowly but surely giving a chance for every task to become the “leftmost task” and thus get allocated CPU resources within a deterministic amount of time.
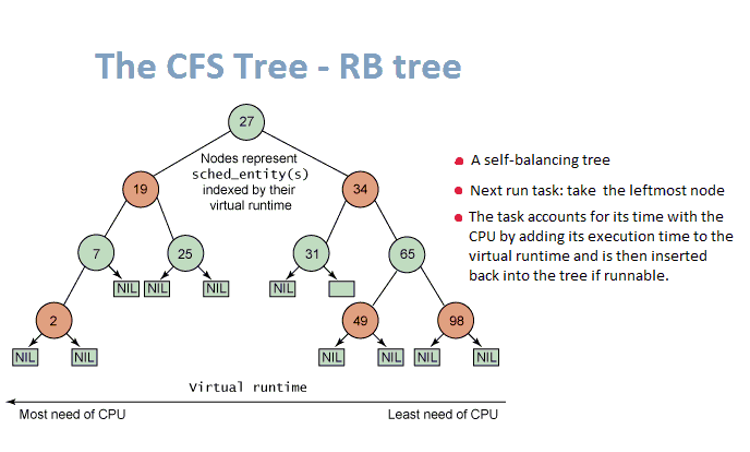
Currently, most Linux container runtime engines are built on the subsystem of cgroup and its CPU scheduler is also under the OS CFS by default. Thus, each cgroup will own its “virtual runtime” subsystem in the OS scheduler. When the OS scheduler starts a cgroup turn, this cgroup takes up its own CPU slices and yield its turn to next “virtual runtime.” Scheduling cgroups in CFS requires us to think in terms of time slices instead of processor counts. The CPU cgroup subsystem is in charge of scheduling and can be tuned to support relative minimum resources as well as hard-ceiling enforcements used to cap process tasks from using more resources than provisioned.
The following figure explains how Linux scheduler handles the CFS virtual runtime during the CFS scheduling class.
The Challenges Ahead
Sadly, you cannot designate a higher priority task under CFS. In this design, IO-intensive tasks which need IO-waits and syscalls will tend to stay at the right side. Because those tasks will frequently take short CPU shares, into an io-wait stage, then yield to next task, the CFS tree will move the task node to the right-side slowly and eventually reduce its priority.
Because of the dynamic balance of the CFS tree, the tasks inside a cgroup cannot demand equal usage of the CPU. When tasks in a cgroup are idle and it will yield its CPU shares, the leftover time is collected in a global pool of unused CPU cycles. Other cgroups are allowed to “borrow” CPU shares from this pool.
Also, you need to understand the tasks attached to its CFS’s queue will share your CPU resources. With such limitations, we cannot achieve a complete real-time container under CFS but a soft real-time container is possible. By ‘soft’ we mean that the usefulness of a result degrades after its deadline, therefore degrading the system’s quality of service.
Final Thoughts
To conquer the challenges of highly threaded, I/O intensive container applications, programmers need to understand how the CFS mechanisms work to balance its RB tree, and how to promote the desired task to get a higher chance to stay at the leftmost nodes of the RB tree. Techniques for optimizing your application to perform best are highly dependent on the characteristics and behavior of your tasks, and you should experiment with different approaches to observe the behavior under stress.
Furthermore, you need to take into consideration the fact that Kubernetes provides another layer of a POD management concept with its CPU manager, which also incorporates the CFS mechanisms. Experimenting with these Kubernetes concepts can also help to achieve your container runtime performance goals.
I hope this post will help you to understand the default runtime scheduler of Linux cgroup subsystems. When you plan to implement a soft real-time container on Linux, you will need a deeper investigation of these CFS characteristics to start your journey.