Jira as Requirements Management Tool (RMT)
Safety-critical industries can be flippantly defined as those where a software failure could kill you. Think automotive, aviation, or medical devices as examples. Safety-critical industries use heavy processes to ensure that (especially but not exclusively) software is developed in a safe manner. Heavy processes often need heavy tools. In terms of requirements management, those heavy requirements management tools (RMT*) include DOORS, DOORS Next Generation, Polarion, Jama, just to name drop a few. These heavy RMTs require a substantial investment of time and money to use properly.
I’ve been a requirements engineer for many years and I’ve done time at avionics and automotive suppliers who had the resources to deploy those heavy RMTs. I’m used to having their advanced features at my fingertips. Now I’m the requirements engineer for the Automotive Linux Team here at SUSE and it’s my job to use the resources available to me to successfully manage requirements for our automotive projects. We took a long hard look at investing resources into a heavy RMT. But we already had Jira in place, so we took up the challenge to see if it could serve as our RMT.
Jira was never designed to be an RMT. Jira was designed to be a bug and issue tracker. But it has the core features of RMTs: individually addressable objects (issues) with attributes (fields) that can be linked to each other. The rest is just presentation. So at its heart, Jira provides the core functionality of an RMT; we just need to work on supplementing its presentation.
Setting up vanilla Jira (no plugins**) as an RMT is a straightforward affair. You create some issue types to represent your requirement types (e.g. stakeholder requirements, system requirements, software requirements). You make a list of the attributes each requirement type will need. For instance, you might need something to indicate whether the requirement is ‘functional’ or ‘non-functional’. You might need a text field to hold the rationale for why the requirement is needed. Et cetera et cetera. You map those needs to existing fields (e.g. requirement text in Description field) or create custom fields and flags to hold the data. You create or re-use link types to link your requirements together. Once that’s all implemented, you can search, view, create, modify, and link requirements just like any other heavy RMT, maybe not as efficiently, but same results nonetheless.
With this Jira-as-RMT setup in place, you can happily start populating the project with your requirements. Eventually you will need to create output for someone to read. There are three key output documents in requirements management and for the sake of this example I will stick to software requirements. The first is the requirements management plan (RMP) that describes how you manage requirements. This is typically a free written document, i.e. it’s not generated from data. Jira is no help here. You might use its cousin Confluence to write your RMP, or Word, or whatever. The second key output document has many names, but we’ll call it the software requirements specification (SRS). The SRS should include all the applicable software requirements of the project plus extra sections about assumptions and a little something about architecture and other explanatory material to help the reader understand the project’s software requirements including liberal use of images and tables. This document can be created in Confluence (the “extra sections”) and use embedded Jira filters to include the requirements themselves. One can imagine other ways, e.g. dump the Jira requirements to individual Word documents and merge them together with the extra sections.
The third key output document is called the trace matrix (TM). This is the tricky one for Jira. The TM is typically a spreadsheet that enumerates each unique path through linking requirements. For example, given a set of stakeholder requirements, linked to your system requirements, linked to your software requirements, linked to test cases and results, the TM would show each unique path from each stakeholder requirement down to a test result. If you image the requirements and test cases as nodes, and the links as edges, the entire set constitutes a graph and you’re doing a depth-first search (DFS) starting at the stakeholder requirements. The main purpose of the TM is to analyze these paths to ensure that each requirement is completely covered by lower-level requirements and eventually tested. We can also use the TM (especially when viewed by a proper spreadsheet program like Excel) to filter and search for requirements based on linking, which is something that cannot be done in vanilla Jira.
Vanilla Jira has no way to create a TM. We solve this problem with a Ruby*** script. Essentially, we export Jira data to comma-separated value (CSV, text-based spreadsheet) files, read that data into a Ruby script where it is processed into graph data structures and the unique paths calculated with a DFS algorithm. Then the paths are output to another CSV.
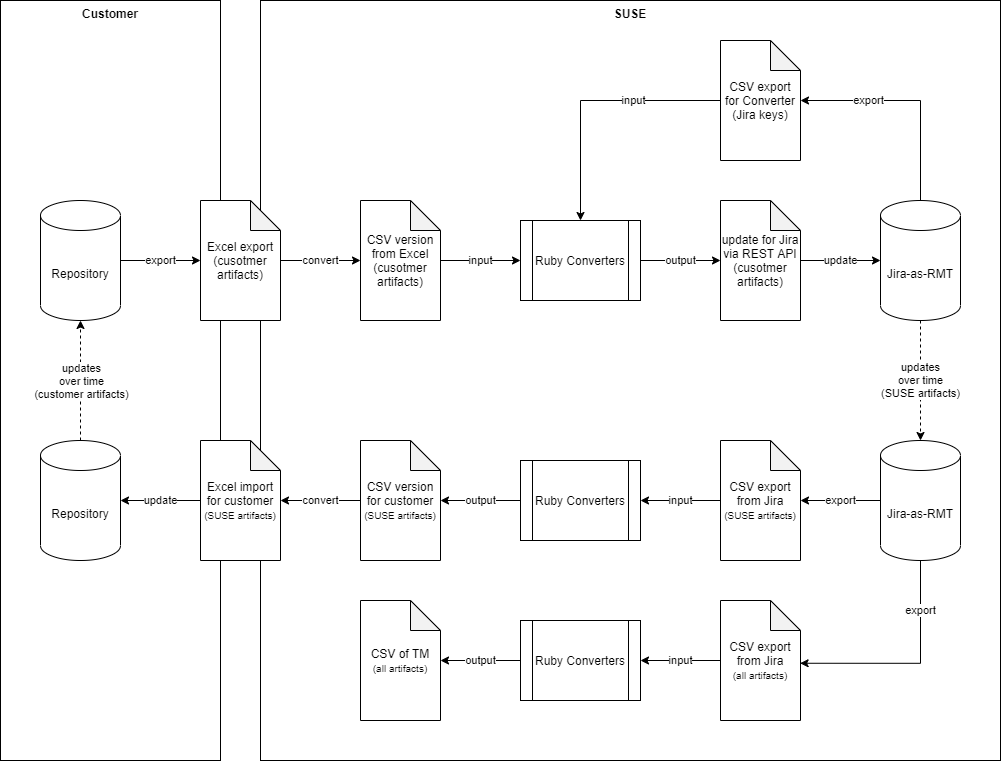
We use Ruby in other ways to supplement our Jira-as-RMT. We get Excel spreadsheets for updates to the customer requirements. These are processed by a Ruby script to transform the data into something that can be imported to Jira using its REST API (that script is written in Python). We also have a Ruby script that generates CSV files that can be uploaded to a Neo4j graph database. Using a Neo4j Desktop browser we can generate a simple, but expressive, graph to visualize the linking between requirements.
Generating a TM, linking visualization, searching based on linking: all of these aspects are normally part of the aforementioned heavy RMTs but needed to be solved with supporting scripts for Jira. But now I must confess that we don’t use vanilla Jira here at SUSE. We also use the Structures plug-in. I must admit that Structures are essential to my everyday use of Jira-as-RMT. I grew up as an engineer using Excel spreadsheets for everything. Heavy RMTs usually have a matrix-style method of visualization and interaction (rows as requirements, columns as attribute values). So Structures in Jira are a very natural way for me to interact with the requirements data and if I didn’t have Structures I would probably have given up.
(Also, I would be remiss if I did not mention one glaring deficiency with Jira-as-RMT: no baselining. Vanilla Jira does not have a baseline mechanism. This blows up many requirements management strategies, especially in safety-critical industries where baselining figures strongly into their certification criteria. We argue that proper versioning the output documents can take the place of in-tool baselines.)
So using Jira as a requirements management tool (RMT) for a safety-critical industry project is possible. SUSE is doing it… wiiiiiith a little help from our scripting friends.
FYI: comments and discussion of this article appear on my LinkedIn post.
* Not to be confused with SUSE’s Repository Mirroring Tool (also RMT), implemented in Ruby, which allows you to “mirror RPM repositories in your own private network”.
** Here is where you, my dear audience, shall pepper the comments section with Atlassian Marketplace Jira plug-ins that solve all the issues I describe and script around in this post. And that’s great! Perhaps we at SUSE will use those plug-ins in the future. Perhaps others will use that information to make their lives easier. More data, more the better.
*** I love Ruby almost as much as I love DOORS. Ruby may not be as popular as Python but it’s the first (and to date only) programming language that I’ve used where: when presented with a problem, I think about how to solve the problem in general computer science terms/data structures/algorithms rather than how to solve the problem using the language. Ruby has a large, dedicated community and libraries (aka gems) for just about anything you can imagine.
Related Articles
Sep 29th, 2023
It’s a New Dawn for SUSE Manager
Oct 18th, 2023