HPC如何推动基因组大数据时代
作者:Jeff Reser
细菌、草和人体有什么共同之处?
表面上看,很少。但是,看到此博客的标题,您可能早就想到了,在细胞水平上,它们都利用了同样出色的基因数据库来控制它们的外观,以及它们的发育、功能和行为。
 这种极其复杂的信息阵列被编码到存在于每个生物体每个细胞中的 DNA 分子中。DNA 实际上是一本手册或蓝图,它以化学形式包含了所有的基本信息和指令,用于生物体的构建、生长和维持。
这种极其复杂的信息阵列被编码到存在于每个生物体每个细胞中的 DNA 分子中。DNA 实际上是一本手册或蓝图,它以化学形式包含了所有的基本信息和指令,用于生物体的构建、生长和维持。
现在,我们正在进行一场探索之旅,以解开隐藏在 DNA 微观结构中的更多秘密。这是一个对我们所有人来说都有着巨大潜力的研究领域;小到促进粮食生产,大到帮助我们了解、诊断、治疗和治愈多种疾病。
为什么我对此特别感兴趣?那是因为,Linux 和高性能计算 (HPC) 是这一领域所有研究和突破背后的关键促成科技。
基因组研究的时代
我们所有的基因信息都携带在两条 DNA(脱氧核糖核酸)链中,它们以双螺旋形状相互缠绕。1953 年弗朗西斯·克里克 (Francis Crick) 和詹姆斯·沃森 (James Watson) 首次正确识别了这种分子结构。但是直到 2003 年 4 月人类基因组计划 (Human Genome Project) 完成后,人类基因组(专业术语,表示我们所有的 DNA)中的所有基因信息才被成功识别、测序和绘制出来。
这个庞大的国际科研项目历时 13 年,耗资约 27 亿美元。但这并不奇怪,因为 DNA 是一种神奇而复杂的物质。
 人类基因组计划完成至今只有 17 年。在那期间,对部分或整个人类基因组进行测序所需的成本和时间都已经大幅削减。如今,基因检测已变得司空见惯,通常可以在几周内完成。
人类基因组计划完成至今只有 17 年。在那期间,对部分或整个人类基因组进行测序所需的成本和时间都已经大幅削减。如今,基因检测已变得司空见惯,通常可以在几周内完成。
这意味着我们现在可以轻松绘制出任何个体的基因组,从而实现更精确的医学治疗,也让构建和维护真实基因信息深层、广泛的数据库成为可能。有了这样的大数据水平,我们就可以开始对基因信息进行大规模自动化分析,帮助改善全民的医疗保健。
我的要点
毫无疑问,我们生活在一个美好的时代。下面说说我的一些想法:
- 开源研究的好处
人类基因组计划是大规模国际合作的典范,需要一个紧密协调和协作的团队来努力完成。一旦人类基因组被成功测序和解码,就会立即被公开。从那时起,新的信息会定期发布并免费提供。在 SUSE,我们完全投入到这个社区推动的“开源”理念中。它渗透到我们所做的每一件事中。
- DNA 在数据存储方面是惊人的
据估计,今年地球上每一个人每秒将产生 7MB 的数据。每年产生的新数据数量都是惊人的。这也意味着我们的数据存储问题迫在眉睫。幸运的是,DNA 使我们能够精确地存储大量数据,其密度远远高于我们目前使用的任何电子设备。不但很稳定,而且非常节能。这听起来像是科幻小说,但就在去年,维基百科上的所有信息都被成功编码到合成 DNA 中。所以,看看这个余地…
- HPC 解决方案在经济和性能方面的改进
1990 年至 2003 年间的人类基因组计划是生物信息学的一次胜利。这是一个多学科的科学领域,融合了生物学、计算机科学、软件工具、信息工程、数学和统计学。出于明显的理由,该项目需要使用超级计算机来处理所有相关的数字运算。从下图可以看出,人类基因组测序的成本在这些年里急剧下降。
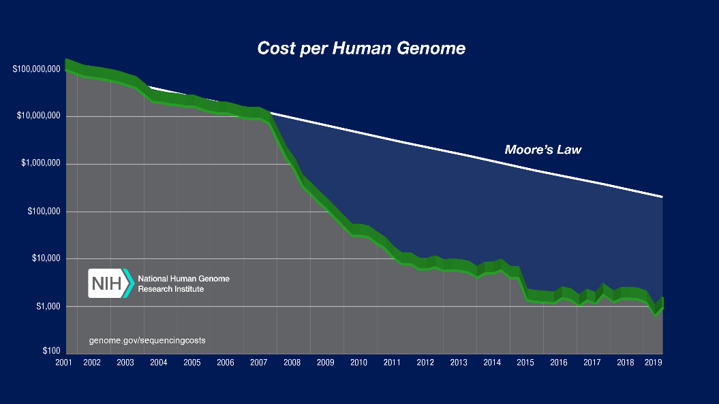
图片来源:国家人类基因组研究所
这有两个原因。一是基因测序方法的进步,自动化程度更高,产量更高。另一个是超级计算机性能和经济效益的大幅提高。如今最快的方式比十年前的任何方式都快 85 倍。现在,所有世界 500 强公司都在 Linux 上运行,这确保了更高的成本效益。
SUSE 在为 HPC 环境定制 Linux 方面处于领先地位。建议您花点时间了解一下以下两个链接提供的信息:
No comments yet