How Does Kubernetes Work?
How Does Kubernetes Work? An In-Depth Overview for Beginners
Introduction
In today’s rapidly evolving digital landscape, understanding Kubernetes has become essential for anyone involved in the world of software development and IT operations. Kubernetes, often abbreviated as K8s, is an open source platform designed to automate deploying, scaling, and operating application containers. Its rise to prominence is not just a trend but a significant shift in how applications are deployed and managed at scale.
Why Understanding Kubernetes is Important
For beginners, Kubernetes can seem daunting; its ecosystem is vast, and its functionality is complex. However, diving into Kubernetes is more than a technical exercise—it’s a necessary step for those looking to stay ahead in the tech industry. Whether you’re a developer, a system administrator, or someone curious about container orchestration, understanding Kubernetes opens doors to modern cloud-native technologies.
The importance of Kubernetes stems from its ability to streamline deployment processes, enhance scalability, and improve the reliability and efficiency of applications. It’s not just about managing containers; it’s about embracing a new paradigm in application deployment and management. With companies of all sizes adopting Kubernetes, knowledge of this platform is becoming a key skill in many IT roles. Additionally, Kubernetes monitoring plays a crucial role in ensuring system health, optimizing performance, and identifying potential issues before they impact applications.
In this article, we will explore the fundamentals of Kubernetes: how it works, its core components, and why it’s become an indispensable tool in modern software deployment. Whether you’re starting from scratch or looking to solidify your understanding, this overview will provide the insights you need to grasp the basics of Kubernetes.
Kubernetes Basics
What is Kubernetes?
Kubernetes is an open source platform designed to automate the deployment, scaling, and operation of application containers. It was originally developed by Google and is now maintained by the Cloud Native Computing Foundation.
Definition and Purpose
At its core, Kubernetes is a container orchestration system. It manages the lifecycle of containerized applications and services, ensuring they run efficiently and reliably. The main purpose of Kubernetes is to facilitate both declarative configuration and automation for application services. It simplifies the process of managing complex, containerized applications, making it easier to deploy and scale applications across various environments.
The Evolution of Kubernetes
Kubernetes has evolved significantly since its inception. It was born from Google’s experience running production workloads at scale with a Borg system. This evolution reflects the growing need for scalable and resilient container orchestration solutions in the industry. Today, many organizations leverage cloud managed Kubernetes solutions to simplify the complexities of running Kubernetes in production environments.
Key Concepts
Containers and Container Orchestration
Containers are lightweight, standalone packages that contain everything needed to run a piece of software, including the code, runtime, system tools, libraries, and settings. Container orchestration is the process of automating the deployment, management, scaling, networking, and availability of container-based applications.
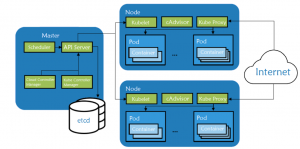
Nodes and Clusters
A Kubernetes cluster consists of at least one master node and multiple worker nodes. The nodes are machines (VMs or physical servers) that run applications and workloads as containers. A cluster is a set of nodes that work together to run containerized applications.
Pods and Services
A pod is the smallest deployable unit in Kubernetes, often containing one or more containers. Services in Kubernetes are an abstraction that defines a logical set of pods and a policy by which to access them, often through a network.
Components of Kubernetes
Kubernetes is an intricate system made up of several components working in harmony to provide a seamless method of deploying and managing containerized applications. Understanding these components is crucial for anyone looking to utilize Kubernetes effectively.

Master Node
The Master Node is the heart of the Kubernetes architecture, responsible for the global management of the cluster. It makes decisions about the cluster (such as scheduling applications), detecting and responding to cluster events (like starting up a new pod when a deployment’s replicas field is unsatisfied).
Control Plane Overview
The Control Plane is a collection of processes that control Kubernetes nodes. This is where all task assignments originate. It includes the Kubernetes Master and kube-system namespace components that run on the master node. The Control Plane’s main function is to maintain the desired state of the cluster, as defined by the Kubernetes API.
API Server, Scheduler, and Controller Manager
- API Server: The API Server is a key component and serves as the front end for the Kubernetes control plane. It is the only Kubernetes component that connects with the cluster’s shared data store etc.
- Scheduler: The Scheduler watches for newly created Pods with no assigned node and selects a node for them to run on.
- Controller Manager: This component runs controller processes, which are background threads that handle routine tasks in the cluster.
- etcd: Consistent and highly-available key value store used as Kubernetes’ backing store for all cluster data.
Worker Nodes
Worker nodes run the applications and workloads. Each worker node includes the services necessary to manage the lifecycle of Pods, managed by the control plane. A Kubernetes cluster typically has several worker nodes.
Understanding Node Agents
Node agents, or “Kubelets,” are agents that run on each node in the cluster. They ensure that containers are running in a Pod and communicate with the Master Node, reporting back on the health of the host it is running on.
Container Runtime (docker)
The Container Runtime is the software responsible for running containers. Kubernetes is compatible with several runtimes including containerd, CRI-O, I.E.. ‘Containerd is the Container Runtime that docker uses.
Deploying Applications in Kubernetes
Deploying applications in Kubernetes is a structured and systematic process, involving several key concepts and tools. Understanding these elements is crucial for efficient and scalable application deployments.
Creating Deployments
Deployments are one of the most common methods for deploying applications in Kubernetes. They describe the desired state of an application, such as which images to use, how many replicas of the application should be running, and how updates should be rolled out. Deployments are managed through Kubernetes’ declarative API, which allows users to specify their desired state, and the system works to maintain that state.
Understanding Pods and ReplicaSets
- Pods: A Pod is the basic execution unit of a Kubernetes application. Each Pod represents a part of a workload that is running on your cluster. A pod typically contains or or more containers.
- ReplicaSets: A ReplicaSet ensures that a specified number of pod replicas (duplicate or copy) are running at any given time. It is often used to guarantee the availability of a specified number of identical Pods.
YAML Configuration Files
Kubernetes objects are often defined and managed using YAML configuration files. These files provide a template for creating necessary components like Deployments, Services, and Pods. A typical YAML file for a Kubernetes deployment includes specifications like the number of replicas, container images, resource requests, and limits.
Scaling Applications
Scaling is a critical aspect of application deployment, ensuring that applications can handle varying loads efficiently.
- Horizontal Scaling: This involves increasing or decreasing the number of replicas in a deployment. Kubernetes makes this easy through the ReplicaSet controller, which manages the number of pods based on the specifications in the deployment.
- Vertical Scaling: This refers to adding more resources to existing pods, such as CPU and memory.
Auto Scaling
Kubernetes also supports automatic scaling, where the number of pod replicas in a deployment can be automatically adjusted based on CPU usage or other select metrics. This is achieved through the Horizontal Pod Autoscaler, which monitors the load and automatically scales the number of pod replicas up or down.
Service Discovery and Load Balancing in Kubernetes
In Kubernetes, service discovery and load balancing are fundamental for directing traffic and ensuring that applications are accessible and efficient. Understanding these concepts is key to managing Kubernetes applications effectively.
Services in Kubernetes
Services in Kubernetes are an abstraction that defines a logical set of Pods and a policy by which to access them. Services enable a loose coupling between dependent Pods. There are several types of Services in Kubernetes:
- ClusterIP: This is the default Service type, which provides a service inside the Kubernetes cluster. It assigns a unique internal IP address to the service, making it only reachable within the cluster.
- NodePort: Exposes the service on each Node’s IP at a static port. It makes a service accessible from outside the Kubernetes cluster by adding a port to the Node’s IP address.
- LoadBalancer: This service integrates with supported cloud providers’ load balancers to distribute external traffic to the Kubernetes pods.
- ExternalName: Maps the service to the contents of the externalName field (e.g., foo.bar.example.com), by returning a CNAME record with its value.
How Services Work
Services in Kubernetes work by monitoring constantly which Pods are in a healthy state and ready to receive traffic. They direct requests to appropriate Pods, thereby ensuring high availability and effective load distribution.
Ingress Controllers
Ingress Controllers in Kubernetes are used for routing external HTTP/HTTPS traffic to services within the cluster. They provide advanced traffic routing capabilities and are responsible for handling ingress, which is the entry point for external traffic into the Kubernetes cluster.
Routing Traffic to Services
Routing traffic in Kubernetes is primarily handled through services and ingress controllers. Services manage internal traffic, while ingress controllers manage external traffic.
TLS Termination
TLS Termination refers to the process of terminating the TLS connection at the ingress controller or load balancer level. It offloads the SSL decryption process from the application Pods, allowing the ingress controller or load balancer to handle the TLS encryption and decryption.
Kubernetes Networking
Understanding networking in Kubernetes is crucial for ensuring efficient communication between containers, pods, and external services. Kubernetes networking addresses four primary requirements: container-to-container communication, pod-to-pod communication, pod-to-service communication, and external-to-service communication. For more information regarding Kubernetes Networking check out our “Deep Dive into Kubernetes Networking” white paper.
Container Networking
In Kubernetes, each Pod is assigned a unique IP address. Containers within a Pod share the same network namespace, meaning they can communicate with each other using localhost. This approach simplifies container communication and port management.
Pod-to-Pod Communication
Pods need to communicate with each other, often across different nodes. Kubernetes ensures that this communication is seamless, without the need for NAT. The network model of Kubernetes dictates that every Pod should be able to reach every other Pod in the cluster using their IP addresses.
Network Policies
Network policies in Kubernetes allow you to control the traffic between pods. They are crucial for enforcing a secure environment by specifying which pods can communicate with each other and with other network endpoints.
Cluster Networking
For cluster-wide networking, Kubernetes supports various networking solutions like Flannel, Calico, and Weave. Each of these offers different features and capabilities:
- Flannel: A simple and easy-to-set-up option that provides a basic overlay network for Kubernetes.
- Calico: Offers more features including network policies for security.
- Weave: Provides a resilient and simple network solution for Kubernetes, with built-in network policies.
These network plugins are responsible for implementing the Kubernetes networking model and ensuring pods can communicate with each other efficiently.
Networking Challenges and Solutions
Kubernetes networking can present challenges such as ensuring network security, managing complex network topologies, and handling cross-node communication. Solutions like network policies, service meshes, and choosing the right network plugin can help mitigate these challenges, ensuring a robust and secure network within the Kubernetes environment.
Managing Storage in Kubernetes
Effective storage management is a critical component of Kubernetes, enabling applications to store and manage data efficiently. Kubernetes offers various storage options, ensuring data persistence and consistency across container restarts and deployments.
Volumes and Persistent Storage
In Kubernetes, a volume is a directory, possibly with some data in it, which is accessible to the containers in a pod. Volumes solve the problem of data persistence in containers, which are otherwise ephemeral by nature. When a container restarts or is replaced, the data is retained and reattached to the new container, ensuring data persistence. For more information, refer to the official Kubernetes documentation on storage
Understanding Volume Types
Kubernetes supports several types of volumes:
- EmptyDir: A simple empty directory used for storing transient data. It’s initially empty and all containers in the pod can read and write to it.
- HostPath: Used for mounting directories from the host node’s filesystem into a pod.
- NFS: Mounts an NFS share into the pod.
- CSI (Container Storage Interface)– Makes it easy to expand k8s’ beyond the built in Storage capabilities. It can add over 80 additional storage devices nfs is not part of K8s storage but is added on via CSI.
- PersistentVolume (PV): Allows a user to abstract the details of how the storage is provided and how it’s consumed.
- ConfigMap and Secret: Used for injecting configuration data and secrets into pods.
Each type serves different use cases, from temporary scratch space to long-term persistent storage.
Data Persistence in Containers
Data persistence is key in containerized environments. Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) are Kubernetes resources that allow data to persist beyond the lifecycle of a single pod, ensuring data is not lost when pods are cycled.
Storage Classes
StorageClasses in Kubernetes allows administrators to define different classes of storage, each with its own service level, backup policy, or disk type. This abstraction allows users to request a certain type of storage without needing to know the details of the underlying infrastructure.
Provisioning and Management
Storage provisioning in Kubernetes can be either static or dynamic:
- Static Provisioning: A cluster administrator creates several PVs. They carry the details of the real storage, which is available for use by cluster users.
- Dynamic Volume Provisioning: Allows storage volumes to be created on-demand. This avoids the need for cluster administrators to pre-provision storage, and users can request storage dynamically when needed.
Dynamic provisioning is particularly useful in large-scale environments where managing individual storage volumes and claims can be cumbersome.
High Availability and Fault Tolerance in Kubernetes
Kubernetes is designed to offer high availability and fault tolerance for applications running in a cluster, making it an ideal platform for mission-critical applications. These features are achieved through a combination of replication, self-healing mechanisms, and automated management of containerized applications.
Replication Controllers
ReplicationControllers are key components in Kubernetes that ensure a specified number of pod replicas are running at any given time. This not only helps in providing high availability but also aids in load balancing and scaling. If a pod fails, the Replication Controller replaces it, ensuring that the desired number of pods is always maintained.
Ensuring Redundancy
Redundancy is a fundamental aspect of high availability. Kubernetes achieves redundancy by running multiple instances of an application (pods), typically across different nodes. This approach ensures that if one instance fails, other instances can continue to serve user requests, minimizing downtime.
Handling Failures
Kubernetes is designed to handle failures gracefully. It continuously monitors the health of nodes and pods. If a node or pod fails, Kubernetes automatically reschedules the pods to healthy nodes, ensuring the application remains available and accessible.
Self-Healing
Self-healing is one of the most powerful features of Kubernetes. It automatically replaces or restarts containers that fail- reschedules containers when nodes die, kills containers that don’t respond to user-defined health checks, and doesn’t advertise them to clients until they are ready to serve.
Automatic Container Restart
Kubernetes’ ability to automatically restart containers that have failed is crucial for maintaining application continuity. This is managed by the kubelet on each node, which keeps track of the containers running on the node and restarts them if they fail.
Resilience in Kubernetes
Resilience in Kubernetes is not just about keeping applications running, but also about maintaining their performance levels. This involves strategies like rolling updates and canary deployments, which allow for updates and changes without downtime or service disruption.
Monitoring and Logging in Kubernetes
Effective monitoring and logging are essential for maintaining the health and performance of applications running in Kubernetes. They provide insights into the operational aspects of the applications and the Kubernetes clusters, enabling quick identification and resolution of issues.
Kubernetes Monitoring Tools
Kubernetes offers several monitoring tools that provide comprehensive visibility into both the cluster’s state and the applications running on it:
- Prometheus: An open source monitoring and alerting toolkit widely used in the Kubernetes ecosystem. It’s known for its powerful data model and query language, as well as its ease of integration with Kubernetes.
- Grafana: Often used in conjunction with Prometheus, Grafana provides advanced visualization capabilities for the metrics collected by Prometheus.
- Heapster: Although now deprecated, it was traditionally used for cluster-wide aggregation of monitoring and event data.
cAdvisor: Integrated into the Kubelet, it provides container users with an understanding of the resource usage and performance characteristics of their running containers.
Application Insights
Gaining insights into applications running in Kubernetes involves monitoring key metrics such as response times, error rates, and resource utilization. These metrics help in understanding the performance and health of the applications and in making informed decisions for scaling and management.
Logging Best Practices
Effective logging practices in Kubernetes are crucial for troubleshooting and understanding application behavior. Best practices include:
- Ensuring Log Consistency: Logs should be consistent and structured, making them easy to search and analyze.
- Separation of Concerns: Different types of logs (like application logs, and system logs) should be separated to simplify management and analysis.
- Retention Policies: Implementing log retention policies to balance between storage costs and the need for historical data for analysis.
Centralized Logging
In a distributed environment like Kubernetes, centralized logging is essential. It involves collecting logs from all containers and nodes and storing them in a central location. Tools like ELK Stack (Elasticsearch, Logstash, and Kibana) or EFK Stack (Elasticsearch, Fluentd, Kibana) are commonly used for this purpose. Centralized logging makes it easier to search and analyze logs across the entire cluster, providing a unified view of the logs.
Security in Kubernetes
Security is paramount in the realm of Kubernetes, as it deals with complex, distributed systems often running critical workloads. Kubernetes provides several mechanisms to enhance the security of applications and the cluster. Container security platforms like SUSE’s Neuvector are extremely important.
Role-Based Access Control (RBAC)
Role-Based Access Control (RBAC) in Kubernetes is a method for regulating access to computer or network resources based on the roles of individual users within an enterprise. RBAC allows admins to define roles with specific permissions and assign these roles to users, groups, or service accounts. This ensures that only authorized users and applications have access to certain resources.
User and Service Account Management
In Kubernetes, user accounts are for humans, while service accounts are for processes in pods. Managing these accounts involves creating and assigning appropriate permissions to ensure minimal access rights based on the principle of least privilege.
Authorization Policies
Kubernetes supports several types of authorization policies, such as Node, ABAC, RBAC, and Webhook. These policies control who can access the Kubernetes API and what operations they can perform on different resources.
Pod Security Standards
Pod Security Standards (PSS) are a set of predefined configurations for Kubernetes pods that provide different levels of security. These standards are part of Kubernetes, a popular open source platform for automating the deployment, scaling, and management of containerized applications. PSS is designed to provide a clear framework for securing pods in a Kubernetes environment.
The Pod Security Standards are divided into multiple levels, typically including:
- Baseline: The default level that provides minimal security requirements and is meant to ensure that the pod does not compromise the security of the entire cluster. It’s suitable for applications that need a balance between security and flexibility.
- Restricted: This level is more secure and includes policies that are recommended for sensitive applications. It restricts some default settings to harden the pods against potential vulnerabilities.
- Privileged: This is the least restrictive level and allows for the most permissive configurations. It’s typically used for pods that need extensive privileges and is not recommended for most applications due to the potential security risks.
Each of these levels includes a set of policies and configurations that control aspects of pod security, such as:
- Privilege escalation and permissions
- Access to host resources and networking
- Isolation and sandboxing of containers
- Resource restrictions and quotas
The purpose of the Pod Security Standards is to make it easier for administrators and developers to apply consistent security practices across all applications in a Kubernetes environment. By adhering to these standards, organizations can help ensure that their containerized applications are deployed in a secure and compliant manner.
Controlling Pod Behavior
Controlling pod behavior involves restricting what pods can do and what resources they can access. This includes managing resource usage, limiting network access, and controlling the use of volumes and file systems.
Security at the Pod Level
Security at the pod level can be enhanced by:
- Using trusted base images for containers.
- Restricting root access within containers.
- Implementing network policies to control the traffic flow between pods.
Future Trends and Conclusion
The Future of Kubernetes
Kubernetes is continuously evolving, with a strong focus on enhancing its security features. Future trends may include more robust automated security policies, enhanced encryption capabilities, and improved compliance and governance tools.
Final Thoughts and Next Steps for Beginners
For beginners, the journey into Kubernetes can start with understanding the basic concepts, and gradually moving towards more complex security practices. It’s essential to stay updated with the latest Kubernetes releases and security recommendations.
Reach Out to SUSE for Help
For additional support and guidance, reaching out to experts at SUSE can provide valuable insights and assistance in navigating the Kubernetes landscape and ensuring a secure and efficient deployment.
Related Articles
Jul 26th, 2024