Adding own Documents to your Local AI Using RAG
Introduction
This is part 4 of a series on running AI locally on an openSUSE system. Previous parts can be found here:
Generating images with LocalAI using a GPU
Introduction to AI training with openSUSE
Since we have LocalAI running, generated images, text and even trained own LoRAs, another big topic is to make use of LLMs for handling own documents. While it is possible to retrain models with additional date, the method I will explain is called Retrieval-Augmented Generation – short RAG.
This is especially of great interest for companies, since no data will leave the network as everything is processed locally and thus enables on premise AI solutions for document and knowledge base handling. But also for private users this provides a privacy friendly solution for handling own documents with LLMs.
RAG
Since Large Language Models are static databases that only have the knowledge used for training them, they required constant retraining or fine tuning in order to be able to provide up to date information. To improve this situation, Meta introduced a method called Retrieval Augmented Generation (RAG) that combines information retrieval with a text generation LLM. This way its internal knowledge can be modified in an efficient way and without needing retraining of the entire model.
RAG takes an input and retrieves a set of relevant/supporting documents given a source like a pdf or text file. The documents are converted into vectorized data, which is used by a semantic search with the input prompt and the result is fed to the text generating model together with the original prompt, which then produces the final output.
RAG also can be connected to a database or other online sources, in this post I will only cover documents though.
LocalAI
LocalAI does not directly provide support for RAG, this is handled by an application which manages the additional information sources and uses LocalAI to vectorizee and use them with a text generation model. There are several open source applications available that provide RAG functionality, a popular one is Open WebUI, which I will explain on how to setup and use. I’m using the LocalAI All in One containers in this post, as they are providing all required models out of the box. Please read my previous posts on how to install and setup containerized LocalAI as well as enable GPUs for docker.
Please note that when testing the setup on systems without GPU, the embedding for some pdf documents failed with the LocalAI crashing, leading to documents not being properly vectorized. Therefor it is highly recommended to make use of a system with a supported GPU.
Open WebUI
Besides offering RAG functionality, Open WebUI in general provides an improved interface to models running in LocalAI, like saving your conversations or enabling tools to be used by the LLM like web search. For installing and using it with LocalAI, you need a running LocalAI instance that is setup using docker compose.
Installation
Edit the docker-compose.yaml of your existing LocalAI installation and add the lines in red:
services:
api:
image: localai/localai:latest-aio-gpu-nvidia-cuda-12
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/readyz"]
interval: 1m
timeout: 10m
retries: 20
ports:
- 8080:8080
environment:
- DEBUG=true
- MODELS_PATH=/models
- WATCHDOG_IDLE=true
- WATCHDOG_BUSY=true
- WATCHDOG_IDLE_TIMEOUT=50m
- WATCHDOG_BUSY_TIMEOUT=50m
volumes:
- ./models:/models:cached
open-webui:
container_name: open-webui
image:
ghcr.io/open-webui/open-webui:main
ports:
- 3000:8080
volumes:
- ./open-webui:/app/backend/data
restart: always
devices:
- /dev/snd
environment:
- OPENAI_API_KEY=0123456789
- OPENAI_API_BASE_URL=http://api:8080/v1
- AUDIO_STT_OPENAI_API_KEY=0123456789
- AUDIO_STT_OPENAI_API_BASE_URL=http://api:8080/v1
- AUDIO_TTS_OPENAI_API_KEY=0123456789
- AUDIO_TTS_OPENAI_API_BASE_URL=http://api:8080/v1
- IMAGES_OPENAI_API_KEY=0123456789
- IMAGES_OPENAI_API_BASE_URL=http://api:8080/v1
depends_on:
api:
condition: service_healthy
Now simply run docker compose restart in the directory with the yaml file and you should see the Open WebUI container start, once the LocalAI container is healthy. To check if everything works, point the browser to http://localhost:3000 and you should see the Open WebUI login screen:
User management
Upon first use, you’ll need to create an admin account, simply click on sign up, enter a user name (e.g. admin), an email address and a password. This first user will be a system administrator account, which is required for the steps below.
Configuration
Despite telling Open WebUI to use LocalAI as backend via environment variables in the docker-compose.yaml file, some more adjustments need to be made to use LocalAI for RAG. In order to vectorize the provided documents, a so called embeddings model is required that handles this step. Simply use text-embedding-ada-002 provided by the LocalAI AIO containers. To do so, as admin click on your user icon and click Settings->Admin Settings->Documents and change the following entries:
- Switch Embedding Model Engine to OpenAI
- Enter the OpenAI URL: http://api:8080/v1
- Enter the OpenAI key: 0123456789
- Set the embedding engine to text-embedding-ada-002

Prompt without RAG
Now that everything is setup, give it a quick test, to see if everything works well.
- Click New Chat
- Enter a prompt that is asking for information in the data that later is added as RAG
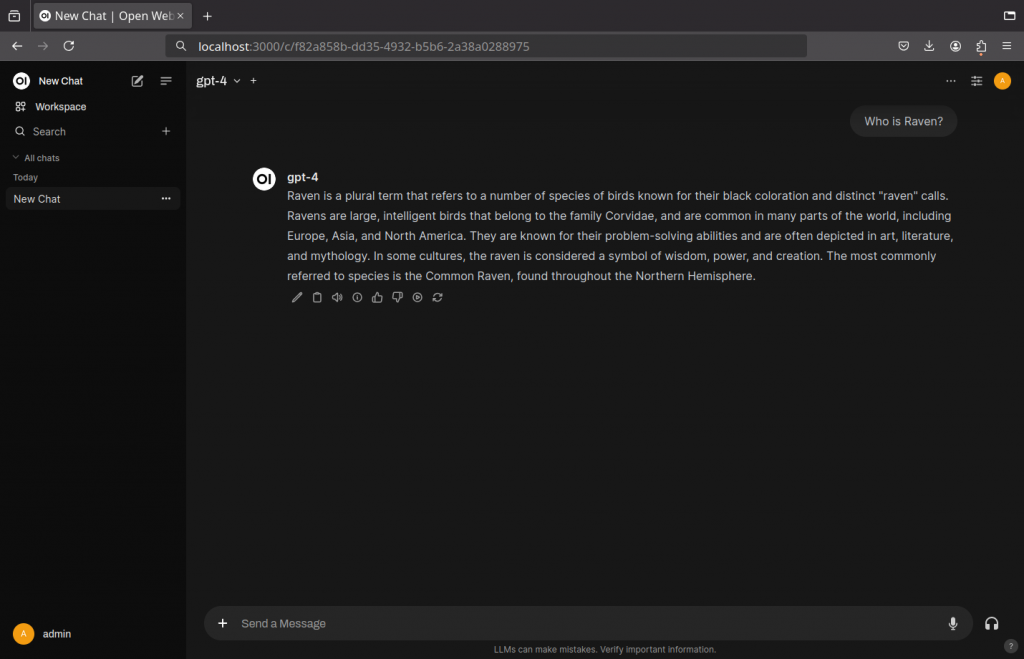
Adding Knowledge
In order to make sure that the added information can’t be already part of the model, I chose the book Snowcrash by Neil Stephenson as additional information to be used by the model.
- Click on Workspace
- Click on Knowledge
- Click the plus icon
- Enter a name for the knowledge base and some description
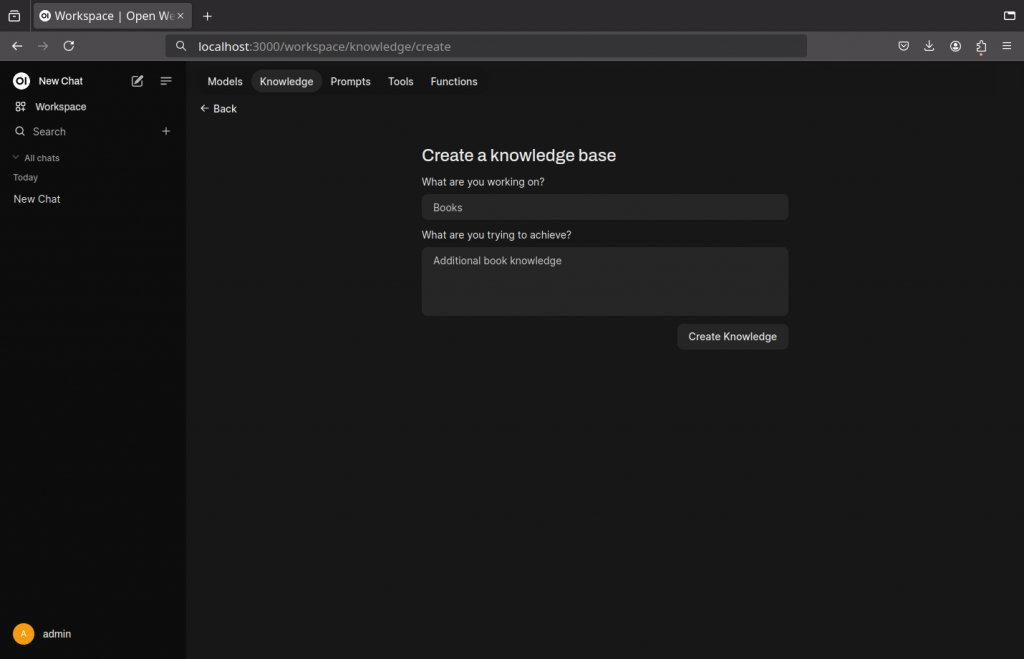
- Click Create Knowledge
- Drag and drop a file containing text (pdf, ascii,…) into the page
- Wait for it getting vectorized by the embeddings model
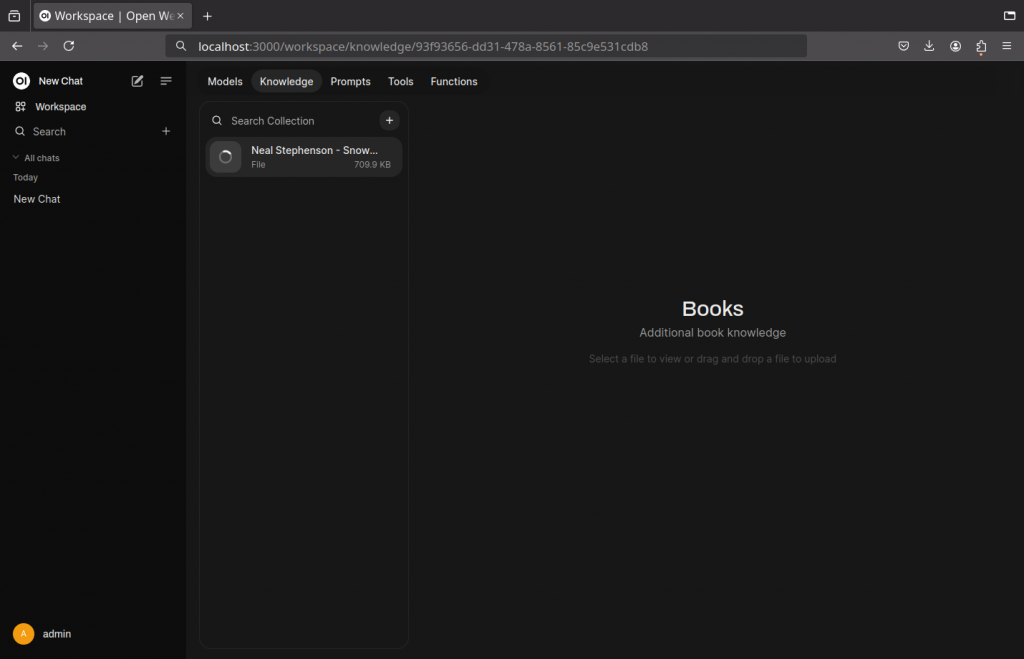
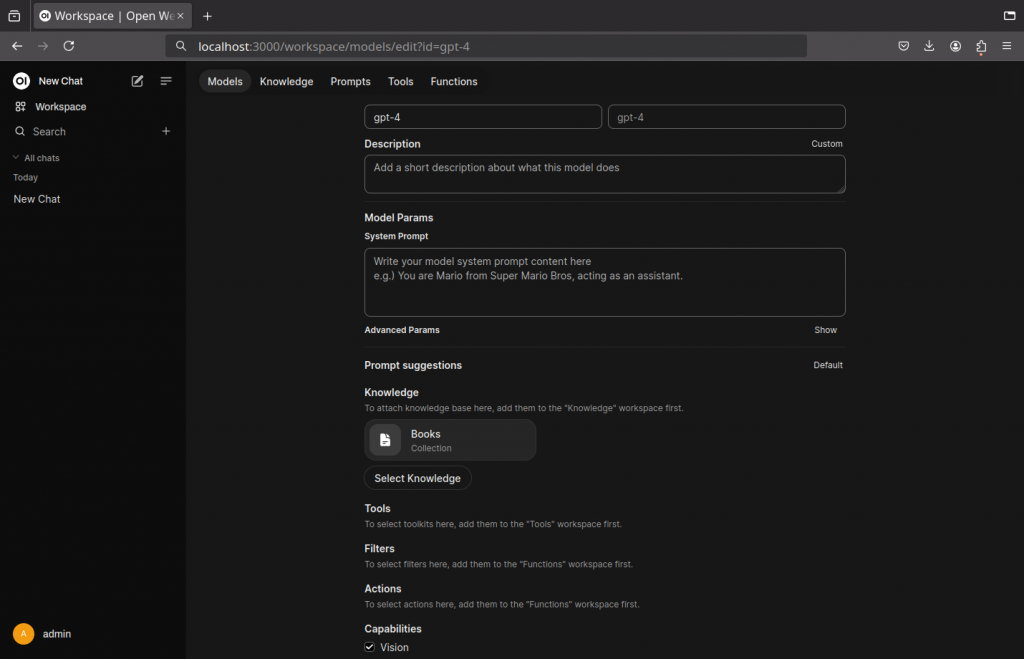
Once a knowledge base is created, it has to be added to a model in order to be used:
- Click on Workspace
- Click on Models
- Choose the model you want to make use of the added documents and click the edit button on the right
- Add the knowledge base you want the model to use
- Click Save & Update
Prompt with RAG
Now, with the model having the knowledge added, give the same prompt again, asking for information provided by the added knowledge base:

As you can see, now the model is taking the provided information into account and changes the answer based on that. Also the used documents are shown, and when you click on them, the sections used in them for the reply are displayed:

Please note that you can get with this setup differing answers for the same prompt.
Summary
RAG provides an easy way to augment exiting models with additional data, which can be easily done locally using open source tools. You can now continue playing with the RAG settings, use different embeddings models or explore the rest of the Open WebUI features like voice conversations and AI tools. In my next post I’ll explain on how to use Open WebUI tools to provide web search functionality to a LLM.
Related Articles
Apr 28th, 2025
Kubernetes Liveness Probes: A Practical Guide
Feb 20th, 2025
No comments yet