Run an Edge AI K3s Cluster on NVIDIA Jetson Nano Boards
Introduction to Edge Artificial Intelligence Proof of Concept
For several years I have worked with customers who wanted to use artificial intelligence (AI) in their products (mostly embedded hardware) but ended up relying on the cloud. With the advances of embedded platforms in recent years, this dependency is gradually disappearing, giving rise to the so-called Edge AI.
Given my professional background and personal interest in this field, I wanted to create a state-of-the-art proof of concept platform with these requirements:
- Standard and low-cost off-the-shelf hardware with GPU acceleration
- Software as standard and open source as possible
- Easy to scale both at hardware and software level (workload distribution and resource optimization)
- Easy integration with existing cloud infrastructures and tools
- Easy and fun to build, test and deploy
To achieve this, we’ll create a low-cost edge AI cluster with full GPU acceleration with NVIDIA Jetson Nano embedded devkits (ARM64 architecture). We’ll also see how to easily manage and integrate these devices with existing clusters in the cloud using K3s, a lightweight Kubernetes distro (created by Rancher Labs and now a CNCF Sandbox project).

Artificial Intelligence Edge Proof of Concept using Jetson Nano Boards
What is Edge Artificial Intelligence (Edge AI)?
But first, what do we mean by edge AI? In edge AI, artificial intelligence algorithms are processed locally on a hardware device without external requirements. The algorithms use data on the device or local cluster. A device using edge AI can process data and make decisions independently without a connection.
This approach has some clear advantages over traditional cloud-based technologies, including:
- Works in situations where external connection is not allowed or generates dependencies in terms of external time and costs
- Requires lower latency to perform tasks since the system has no external dependencies
- Data is processed locally, avoiding the problem of storage and streaming to the cloud, reducing dependencies in terms of privacy and security

Artificial Intelligence Edge proof of concept with Jetson Nano boards and K3s
Platform Choice: NVIDIA Jetson Boards and K3s
NVIDIA’s Jetson family of system on a chip (SoCs) are the most widely used boards in AI projects, robotics and GPU edge computing due to their ARM architecture with GPU and CUDA support. With Kubernetes technology (such as K3s), we can perform cluster training and inference, adding nodes as needed without external dependencies.
For this PoC, I chose two Jetson Nano boards from a previous robotics project. I implemented real-time object tracking and recognition algorithms using Tensorflow (so GPU support was mandatory). While two nodes may not be enough for a production environment in a traditional Kubernetes cluster, scalability for Nano boards is easy with minimal changes in the operating system. Also, cloning mSD cards and using SSD hard disks is easy with this setup.
At the architecture level, we’ll use K3s and standard tools such as Docker, ctr and kubectl.
Docker is the best-known runtime solution and is prevalent in development environments. However, Docker was deprecated as a container runtime for Kubernetes kubelets in December 2020, replaced by runtimes such as containerd. This solution has gained strength as the new industry standard, especially for production deployments (and is the default option in K3s, although you can change this).
For GPU support, we’ll use nVidia tools and libraries available in the latest revision of L4T, including nvidia-container-runtime, deviceQuery and TensorFlow. NVIDIA has supported GPU acceleration in Docker for some time using nvidia-container-runtime. In February 2021, they announced the same GPU acceleration support for containerd with their runc runtime implementation nvidia-container-runtime. In this PoC, we will use both runtimes: Docker for testing GPU standalone containers (as a development environment) and containerd for the Kubernetes cluster (as a production environment), both with GPU support, using nvidia-container-runtime.
Requirements
Hardware
- 2x nVidia Jetson Nano boards
- 2x microSD cards (64GB preferred)
- 2x power supply (5V/4W)
- 2x fan
- 1x cluster case (optional)
- 2x jumper (for switching to high power mode)
Software
- JetPack: 4.5
- L4T: 32.5.0 (included in JetPack 4.5)
- K3s: v1.19.7+k3s1 (arm64 version)
- kubectl: v1.20 (arm64 version)
NOTE – All scripts, configuration files and docker images used are available at :
https://github.com/xiftai/jetson_nano_k3s_cluster_gpu/
and
https://hub.docker.com/orgs/xift/repositories/
Let’s get started!
Process Steps
Linux Base System Setup
To deploy the cluster, the operating system must be configured on all boards as follows:
- 8GB Swap space
Using the script setSwapMemorySize of JetsonHacks available from its repository.
./setSwapMemorySize.sh -g 8
- 4W Power Mode
Connect the J48 jumper (see the Power Guide section of the Jetson Nano Developer Kit User Guide). Power up the boards and then run:
sudo nvpmodel -m 0
- Add each IP and hostname on /etc/hosts file
In our example (just two boards):
192.168.0.34 jetson1
192.168.0.35 jetson2
- Disable IPv6
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=1
nVidia Docker Support
Preinstalled in the L4T image. We can check it is working with:
nvidia-container-runtime --version
Once we’ve made these changes, the operating systems will be ready for the next steps.
Deploy K3s
NOTE: If not otherwise specified, the commands will be executed on all Jetson boards.
Download K3s and kubectl
Start by downloading the K3s and kubectl ARM64 binaries and copy them to /usr/local/bin with execution permissions:
sudo wget -c "https://github.com/k3s-io/k3s/releases/download/v1.19.7%2Bk3s1/k3s-arm64" -O /usr/local/bin/k3s ; chmod 755 /usr/local/bin/k3s
sudo wget -c "https://dl.k8s.io/v1.20.0/kubernetes-client-linux-arm64.tar.gz" -O /usr/local/bin/kubectl ; chmod 755 /usr/local/bin/kubectl
Set up K3s
NOTE: Refer to the Rancher K3s Server and Agent Configuration Reference guides for more info about the parameters used in the config.yaml files.
Master (jetson1)
/etc/rancher/k3s/config.yaml
node-ip: 192.168.0.34
token: PRE_SHARED_TOKEN_KEY
Agent (jetson2)
/etc/rancher/k3s/config.yaml
node-ip: 192.168.0.35
server: https://192.168.0.34:6443
token: PRE_SHARED_TOKEN_KEY
We can apply the same configuration used for the jetson2 node to the rest of the nodes in the cluster in case we use three or more boards.
Launch K3s nodes:
Server node
Master (jetson1)
k3s server -c /etc/rancher/k3s/config.yaml
K3s creates two important files that we will modify for our needs:
/etc/rancher/k3s/k3s.yaml
The above is the Kubernetes configuration file that we need for interacting with the cluster using the kubectl tool. We can use this file in any computer with kubectl to interact with the Kubernetes cluster by changing the server URL to http://192.168.0.34:6443 (our jetson1 address) and setting the KUBECONFIG environment path to this file before the kubectl invocation.
/var/lib/rancher/k3s/agent/etc/containerd/config.toml
The above is the containerd configuration file. It’s generated at each K3s startup, so according to the K3s Advanced Options and Configuration Guide, we can copy it over a template file in the same path named config.toml.tmpl and use it instead. We need to modify this template file to add the nvidia-container-runtime support in containerd, adding the next lines at the end of the file and restarting K3s for the changes to take effect.
[plugins.cri.containerd.runtimes.runc]
runtime_type = "io.containerd.runtime.v1.linux"
[plugins.linux]
runtime = "nvidia-container-runtime"Agent node(s)
Agent (jetson2)
k3s agent -c /etc/rancher/k3s/config.yaml
Use the same command for the rest of the boards in case you use three or more boards.
Check the K3s cluster status and logs
We can check the cluster status with kubectl with the usual commands:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl get nodes
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl get pods --all-namespaces
Testing GPU Support
We’ll use the deviceQuery NVIDIA test application (included in L4T) to check that we can access the GPU in the cluster. First, we’ll create a Docker image with the appropriate software, run it directly as Docker, then run it using containerd ctr and finally on the Kubernetes cluster itself.
Test 1: Running deviceQuery on Docker with GPU support
Copy the demos where deviceQuery is located to the working directory where the Docker image will be created:
cp -R /usr/local/cuda/samples .
Then create the Dockerfile for the deviceQuery image as follows:
Dockerfile.devicequery
FROM nvcr.io/nvidia/l4t-base:r32.5.0
RUN apt-get update && apt-get install -y --no-install-recommends make g++
COPY ./samples /tmp/samples
WORKDIR /tmp/samples/1_Utilities/deviceQuery
RUN make clean && make
CMD ["./deviceQuery"]Build the image (change the name of the tag to whatever you want):
docker build -t xift/jetson_devicequery:r32.5.0 . -f Dockerfile.deviceQuery
Finally, run the Docker container with the nVidia runtime support
docker run --rm --runtime nvidia xift/jetson_devicequery:r32.5.0

If everything went fine (Result = PASS), we can push the image to the Docker Hub repository for the next steps.
NOTE: We provide the created image here for your convenience.
Test 2: Running deviceQuery on containerd with GPU support
Since K3s uses containerd as its runtime by default, we will use the ctr command line to test and deploy the deviceQuery image we pushed on containerd with this script:
#!/bin/bash
IMAGE=xift/jetson_devicequery:r32.5.0
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
ctr i pull docker.io/${IMAGE}
ctr run --rm --gpus 0 --tty docker.io/${IMAGE} deviceQuery

If everything went fine (Result = PASS, same as with Docker), we can move to the final test: running a pod on the K3s cluster.
Final test: Running deviceQuery on the K3s cluster
For this final test, we will create a pod file for deploying on the cluster :
pod_deviceQuery.yaml
apiVersion: v1
kind: Pod
metadata:
name: devicequery
spec:
containers:
- name: nvidia
image: xift/jetson_devicequery:r32.5.0
command: [ "./deviceQuery" ]and then deploy on the cluster with kubectl:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl apply -f ./pod_deviceQuery.yaml
We can check that everything went fine with the kubectl commands:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl describe pod devicequery
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl logs devicequery
If everything went fine (Result = PASS), then we can force the deployment on the second node (jetson2) with the nodeName parameter:
pod_deviceQuery_jetson2.yaml
apiVersion: v1
kind: Pod
metadata:
name: devicequery
spec:
nodeName: jetson2
containers:
- name: nvidia
image: xift/jetson_devicequery:r32.5.0
command: [ "./deviceQuery" ]and then deploy on the cluster with kubectl :
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl apply -f ./pod_deviceQuery_jetson2.yaml
Check if everything went fine on jetson2:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl describe pod devicequery
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl logs devicequery
If everything went fine, congratulations! You’ve got a K3s Kubernetes cluster with GPU support! (Yes, it’s a test image, but it’s still cool.)
Tensorflow GPU Support
Why stop with a test image? For the real thing, we need a fully TensorFlow GPU-supported image. TensorFlow is the most widely used machine learning software platform in production environments today. At the time of writing, an official Tensorflow Docker image for L4T r32.5 is not available, so we need to build it ourselves.
Building and running Tensorflow Docker image with GPU support
Dockerfile.tf
FROM nvcr.io/nvidia/l4t-base:r32.5.0
RUN apt-get update -y
RUN apt-get install python3-pip -y
RUN pip3 install -U pip
RUN DEBIAN_FRONTEND=noninteractive apt-get install libhdf5-serial-dev hdf5-tools libhdf5-dev zlib1g-dev zip libjpeg8-dev liblapack-dev libblas-dev gfortran -y
RUN DEBIAN_FRONTEND=noninteractive apt-get install python3 python-dev python3-dev build-essential libssl-dev libffi-dev libxml2-dev libxslt1-dev zlib1g-dev -yq
RUN pip install -U Cython
RUN pip install -U testresources setuptools==49.6.0
RUN pip install numpy==1.16.1 h5py==2.10.0
RUN pip install future==0.18.2 mock==3.0.5 keras_preprocessing==1.1.1 keras_applications==1.0.8 gast==0.2.2 futures protobuf pybind11
RUN pip3 install -U grpcio absl-py py-cpuinfo psutil portpicker gast astor termcolor wrapt google-pasta
RUN pip3 install --pre --extra-index-url https://developer.download.nvidia.com/compute/redist/jp/v45 tensorflowBuilding:
docker build -t xift/l4t-tensorflow:r32.5.0-tf2.3.1-py3 -f Dockerfile.tf
Running on Docker (as before):
docker run -ti --rm --runtime nvidia xift/l4t-tensorflow:r32.5.0-tf2.3.1-py3
and finally, check the TensorFlow GPU support with:
python3 -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices());"
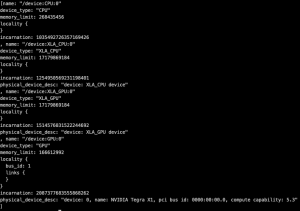
Deploying TensorFlow on the K3s cluster
We create a pod yaml file for deploying:
pod_tf.yaml
apiVersion: v1
kind: Pod
metadata:
name: tf
spec:
containers:
- name: nvidia
image: xift/l4t-tensorflow:r32.5.0-tf2.3.1-py3
command: [ "sleep" ]
args: [ "1d" ]Run it same as before:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl apply -f pod_tf.yaml
Check if it works:
KUBECONFIG=/etc/rancher/k3s/k3s.yaml kubectl exec -it tf -- /bin/bash
python3 -c "from tensorflow.python.client import device_lib; print(device_lib.list_local_devices());"
If everything went fine, we can see that TensorFlow’s GPU detection was correct, as in the previous case.
So that’s it. We have a fully functional Edge AI Cluster with TensorFlow and GPU Support. Now we can use the xift/l4t-tensorflow:r32.5.0-tf2.3.1-py3 base image in any Dockerfile to deploy our Python code and run it with ease.
Conclusion and Future Work
We’ve demonstrated that creating a scalable edge AI cluster of low-cost, high-performance nVidia boards is quite feasible (and fun!) using NVIDIA L4T tools, the lightweight K3s Kubernetes distro and basic container technology.
I would like to thank some very cool people of Rancher Labs (now SUSE): Raúl Sánchez, for his support in developing the idea and telling me about the K3s project. Caroline Kvitka and Mark Abrams for their help in reviewing the article. Thank you all for your help and support. Hope to see you around!
In a future post, I will provide an example with code of distributed training and inference in the cluster for an applied deep learning use case. There are even more interesting approaches at the architecture level, such as creating low-latency distributed clusters using Wireguard and doing hybrid approaches (training in cloud, deployment in edge).
Thanks for reading!
Ready to give it a try? Start by downloading K3s.
Carlos is a multi-disciplinary technology consultant, entrepreneur and professor with more than 25 years of experience in GNU/Linux systems. He is the founder of xift.ai. In his professional career, he has carried out projects focused on open source technologies in all types of systems, embedded hardware, artificial intelligence and cybersecurity, and training in different technology schools. Find him on Linkedin or GitHub.
Related Articles
Nov 18th, 2025
Comments
Thanks for a great article. In your setup, can the jetson devices share workloads? I didn’t see any jetson to jetson hardware connections in the photo.
Also, would you be so kind to share your parts list? I am also interested in clustering some jetsons.