Emergency Braking for SAP HANA Dying Indexserver
In some cases the SAP HANA indexserver is crashing and it takes very long for the service to fail completely. This is the reason why SAP HANA delays to report this failure towards the HA cluster. Obviously in such cases it is extremely helpful to have an emergency braking.

This blog article describes why the SAP HANA indexserver could take very long to die. After that you will learn how SUSE has solved that problem. SUSE’s new solution significantly speeds up the takeover. You will also get a first impression how to implement the new solution and how it is looking in the cluster.
What is the problem with a dying indexserver?
In case of a very big indexserver dying takes very long. We got the information that in some large customer environments it takes often 1.5 hours to get the indexserver completely down and restarted. This downtime is much too long to match the SLAs. Undoubtedly the reason for the slow dying of the indexserver is that it needs to free all the resources. The HDB daemon restarts the failed service only, if it is completely down. SAP HANA keeps reporting the status as “yellow”. Obviously the cluster must not jump-in at yellow level. The following graphic illustrates the slow release of the memory resources.
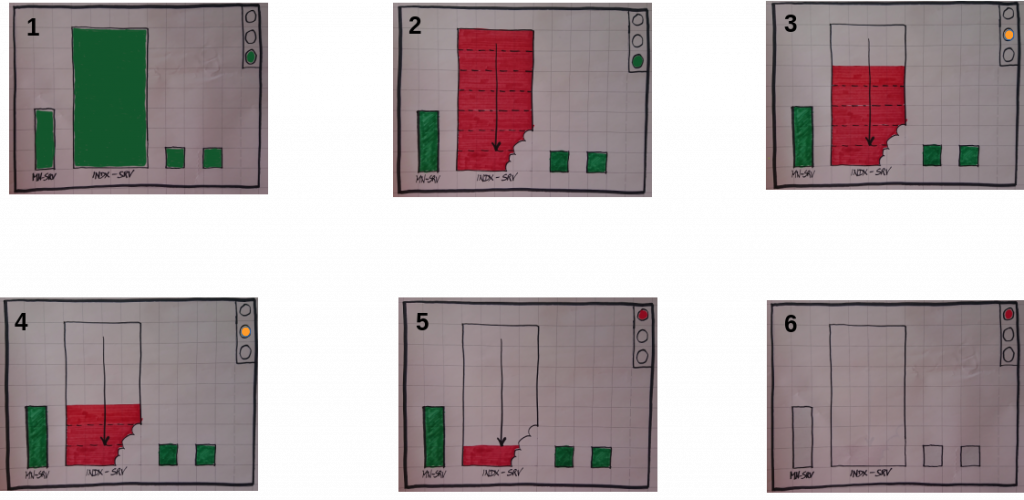
Dying Indexserver is taking too long
This means the cluster action to either restart the SAP HANA database or to trigger a takeover needs to wait. The SAP HANA database finally reports a “red” status. Now the cluster is ready to repair the situation. In summary the slowly dying indexserver delays the cluster action for a too long time.
What is the solution covering the dying indexserver?
The solution uses the SAP HA/DR provider calls. In special the method srServiceStateChanged handles all status changes of any SAP HANA service. On SAP HANA service level the nameserver of the SAP HANA instance is processing this event.
Right after the namserver has detected a status change, it calls the SAP HA/DR provider API. Our solution uses the script susChkSrv.py to cover the SAP HANA srHook method srServiceStateChanged.
This script analyzes the data provided during the call. It checks, if the affected service is an indexserver as well as the event is an indexserver loss. Additionally the hook makes sure it is not just a graceful shutdown or a stop of a single tenant. If the script comes to the conclusion, that the event is an indexserver loss it starts the configured activity.
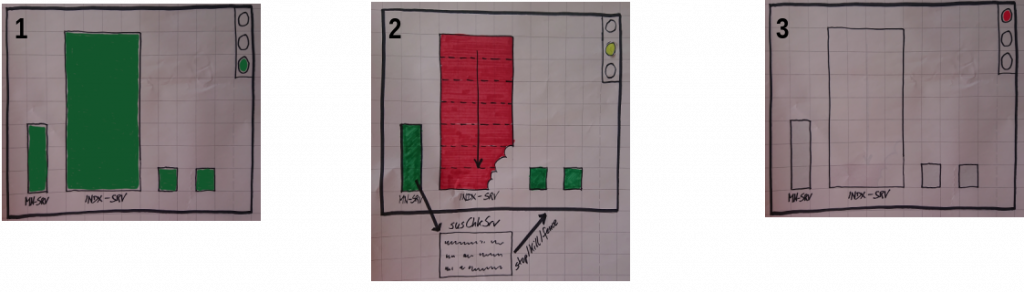
Fast Dying Indexserver
Purpose of susChkSrv.py is to detect failing SAP HANA indexserver processes and trigger a fast takeover to the secondary site. With regular configuration of an HANA database, the resource agent (RA) for SAP HANA in a Linux cluster does not trigger a takeover to the secondary site when:
- Software failures causes one or more SAP HANA processes to be restarted in place by the SAP HANA instance itself.
- Hardware errors (e.g. memory error) causes the indexserver to restart locally.
The nameserver calls the HA/DR provider hook script susChkSrv.py for any srServiceStateChanged event. Next the script filters on the type of service, the type of status change and the current status of the SAP HANA instance and tenant database. If all conditions are matching, susChkSrv.py has identified a “lost indexserver”. In that case it executes the predefined action. This action could be e.g. “stop”, “kill” and “fence”. In consequence of the hook action the SAP HANA database changes its landscape status.
As soon as the SAP HANA landscapeHostConfiguration status changes to 1, the Linux cluster will take action. Surely the action depends on SAP HANA system replication status and the RA´s configuration parameters PREFER_SITE_TAKEOVER and AUTOMATED_REGISTER. This is also described in more detail in the manual pages ocf_suse_SAPHana(7) and ocf_suse_SAPHanaController(7).
Finally tuning of SAP HANA daemon timeout parameters might be needed for adapting the solution to a given environment. Please refer to SAP HANA documentation.
This hook script needs to be installed, configured and activated on all SAP HANA nodes.
Base configuration
The call of the HA/DR provider hook susChkSrv.py is defined in the SAP HANA configuration file global.ini.
Currently the following parameters in global.ini are available:
Section ha_dr_provider_suschksrv
The call out is defined in section “ha_dr_provider_suschksrv”. Additionally the section also covers special parameters of susChkSrv.py.
- provider = susChkSrv
The parameter is mandatory. The value must be susChkSrv to start the correct hook script. - path = /usr/share/SAPHanaSR-angi
The parameter is mandatory. The path depends on the installed RPM package. - execution_order = [ INTEGER ]
The parameter is mandatory. Order might depend on other hook scripts. A best practice first processes the SAPHanaSR.py hook and the susChkSrv.py hook afterwards. Configure a higher execution_order value as for SAPHanaSR.py. - action_on_lost = [ ignore | stop | kill | fence ]
The parameter is optional. The parameter defines the action to be processed in case of a lost indexserver event. The default is “ignore” to just document “lost indexserver” events without jumping in.
It is recommended to set one of the following actions explicitly:
– ignore: do nothing, just write to tracefiles.
– stop: Stop the SAP HANA database system
– kill: Kill the SAP HANA instance. Use the parameter ‘kill_signal’ to define the signal. See also man page signal(7).
– fence: Fence the affected SUSE cluster node. This needs a Linux cluster STONITH method and sudo permission. - kill_signal = [ INTEGER ]
The parameter is optional and only valid for action “kill”. The default is 9. - stop_timeout = [ INTEGER ]
The parameter is optional and only valid for action “stop”. The default is 20. Should be greater than value of daemon.ini parameter ‘forcedtimeout’.
Section trace
The section trace defines the logging level of HA/DR provider hook scripts.
- ha_dr_suschksrv = [ info | debug ]
The parameter is optional. Default is info. However we recommend to set it to “info” explicitly.
Examples
Example for minimal entry in SAP HANA global configuration /hana/shared/$SID/global/hdb/custom/config/global.ini
In case of a failing indexserver, the event is logged. No action is performed (action is “ignore). The section ha_dr_provider_suschksrv is needed on all HANA nodes. To set the section and parameters you should use SAP tools instead of editing the file directly.
[ha_dr_provider_suschksrv]
provider = susChkSrv
path = /usr/share/SAPHanaSR-angi/
execution_order = 3
Example for checking the HANA tracefiles for srServiceStateChanged events
This example uses HA1 as SID. The admin should execute the commands on the respective SAP HANA master nameserver.
If the SAP HANA nameserver process is killed, in some cases hook script actions do not make it into the nameserver tracefile. In such cases the hook script´s own tracefile might help, see respective example.
# su – ha1adm
~> cdtrace
~> grep susChkSrv.*srServiceStateChanged nameserver_*.trc
~> grep -C2 Executed.*StopSystem nameserver_*.trc
Example for getting script load times from SAP HANA tracefiles
This example also uses HA1 as SID. Admins should execute the commands on both sites on the master nameserver nodes.
# su – ha1adm
~> cdtrace
~> grep HADR.*load.*susChkSrv nameserver_*.trc
~> grep susChkSrv.init nameserver_*.trc
Example for checking the hook script tracefile for actions
In this example we demonstrate how to check for hook decisions in the hook’s own SAP HANA trace file nameserver_suschksrv.trc.
The example again uses HA1 as SID. Admins should execute the command on all nodes. All incidents are logged on the SAP HANA nodes where it happens.
# su – ha1adm
~> cdtrace
~> egrep ‘(LOST:|STOP:|START:|DOWN:|init|load|fail)’ nameserver_suschksrv.trc
Example for checking the hook script tracefile for node fencing actions
A bit more specific in this example we check for fencing actions forced by the hook script.
The example again uses HA1 as SID. Admins should execute the commands on both sites’ master nameservers nodes. For additional information see also manual page SAPHanaSR-hookHelper(8).
# su – ha1adm
~> cdtrace
~> grep fence.node nameserver_suschksrv.trc
References
- Manual pages
SAPHanaSR(7), susChkSrv.py(7), SAPHanaSR-hookHelper(8) and SAPHanaSR-manageProvider(8) - Setup guides
https://documentation.suse.com/sbp/sap/ - Blogs
#towardszerodowntime , What is SAPHanaSR-angi? - GithHub projects SAPHanaSR and SAPHanaSR-ScaleOut