SUSE Rancher and Komodor – Continuous Kubernetes Reliability

SUSE guest blog authored by:
Oren Ninio, Head of Solution Architecture at Komodor
The Kubernetes Landscape
With 96% of organizations either using or evaluating Kubernetes and over 7 million developers using Kubernetes around the world, according to a recent CNCF report, it’s safe to say that Kubernetes is eating up the world and has become the de-facto orchestrating system of cloud-native applications.
The benefits of adopting K8s are obvious in terms of efficiency, agility, and scalability. However, despite the project’s maturity, the industry is still developing the knowledge-base, best practices, and tools required to manage day-to-day K8s operations.
The ever expanding K8s landscape is only increasing the complexity that’s already baked into the platform. Making it even harder to build and maintain robust and reliable systems at scale. In fact, according to the latest State of Kubernetes report by VMWare, 95% of respondents stated that they have difficulty in selecting, deploying, and managing K8s, with 51% pointing at the lack of internal experience and expertise, and 34% denoting the speed of changes.
Given all that, it’s no surprise that demand is on the rise for tools that abstract away the complexity under the hood, and consolidate K8s management into a single platform.
SUSE Rancher
Enter SUSE Rancher.
SUSE Rancher is the leading unified, multi-cloud, Kubernetes, and platform-agnostic management tool in the industry. It simplifies K8s management by delivering streamlined cluster operations, full visibility and monitoring, and unified security and governance.
SUSE Rancher consolidates a host of K8s functionalities under one platform, to essentially serve as a one-stop-shop for building, deploying, and scaling containerized applications, including packaging, CI/CD, logging, monitoring, and service mesh.
Furthermore, SUSE Rancher mitigates the complexity of K8s operations, by offering a simple and consistent way to provision, manage versions, gain visibility and diagnostics, set up monitoring and alerting, automating processes and enforcing user access and security policies across clusters.
Komodor – The missing piece
Kubernetes environments are extremely dynamic and flexible. As such, when incidents occur, fixing them without the right context is challenging. Answering a simple question like “who changed what and when?” can be very time consuming and cognitively taxing given the many moving parts of K8s and the sheer amount of metrics, data and logs you need to piece together to get a sense of what the root cause might be.
Komodor complements SUSE Rancher by providing a coherent timeline view of all relevant changes and events in any cluster, as well as historical data that makes it extremely easy to draw insights to investigate incidents and quickly zero in on the root cause. You can even view pod logs directly in the platform without having to give Kubectl access to every developer.
Komodor monitors every K8s resource and ensures compliance with best practices to prevent issues before they happen (i.e liveness probe missing, no CPU limits, etc).
Komodor presents all the relevant data, minus the noise, and provides step-by-step instructions for remediation while automating away all the manual checks usually required when troubleshooting.
Troubleshooting K8s with Komodor
From installation to solving the first issue
To get started with Komodor, simply go to the signup page, and follow the instructions. The installation takes 5 minutes, and is very easy and straightforward, but you can review our documentation and helm charts beforehand.
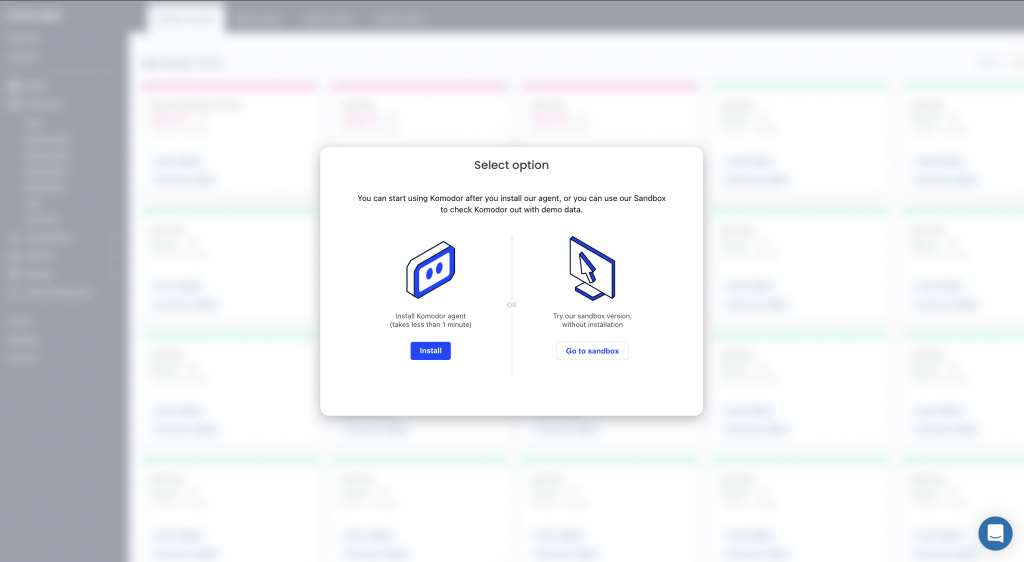
You can also deploy the Komodor agent directly from the SUSE Rancher built-in apps catalog.
After signing up using your email address you will have to add your first cluster. Just click on ‘Add a Kubernetes cluster’ and start typing your cluster’s name.
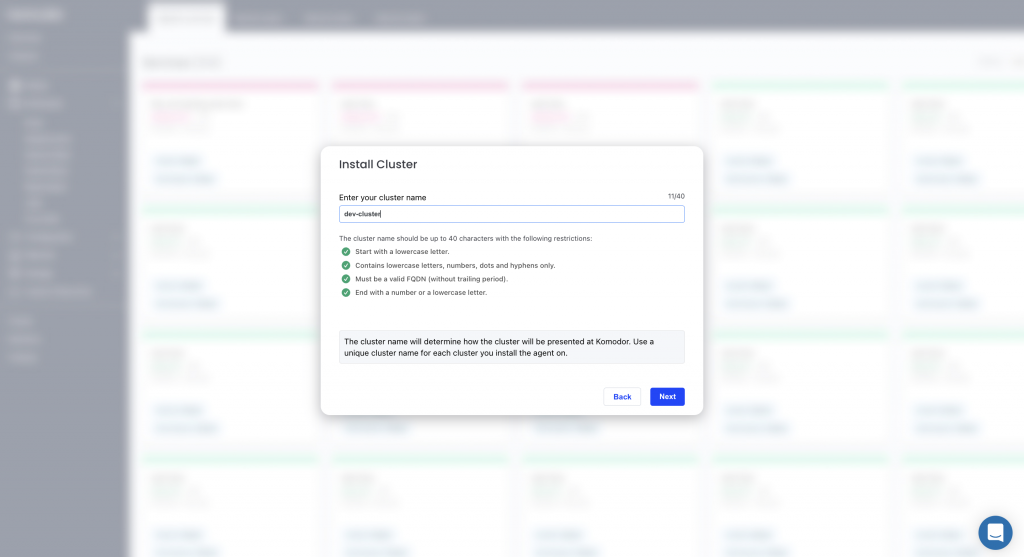
Copy the Helm command and paste it into your terminal to start the installation.
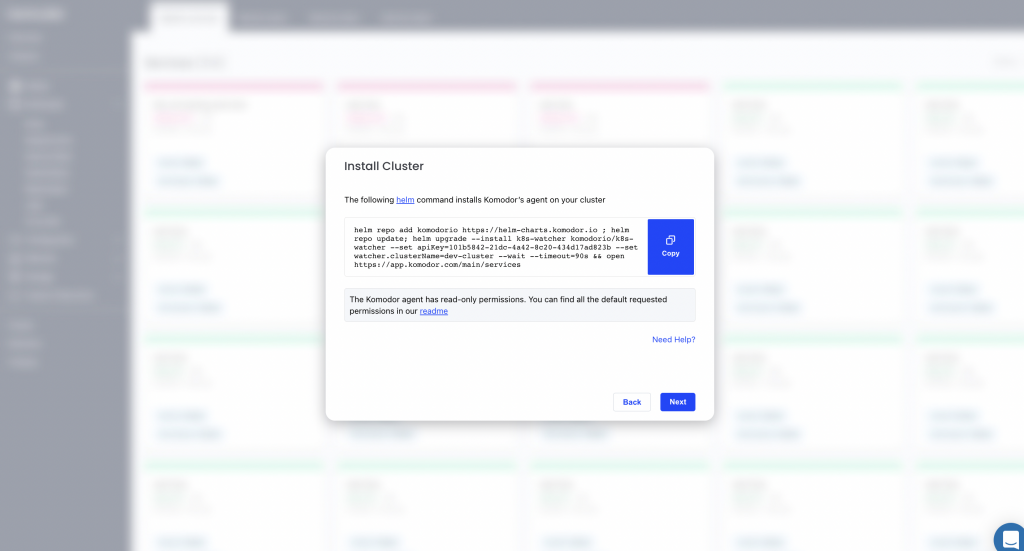
Now you can see every K8s resource on this cluster. You can filter your services by checking any of the filters on the left, or sort them using the dropdown menu on the top right corner.
Komodor will start monitoring changes for each Kubernetes resource and displaying them on a coherent timeline.
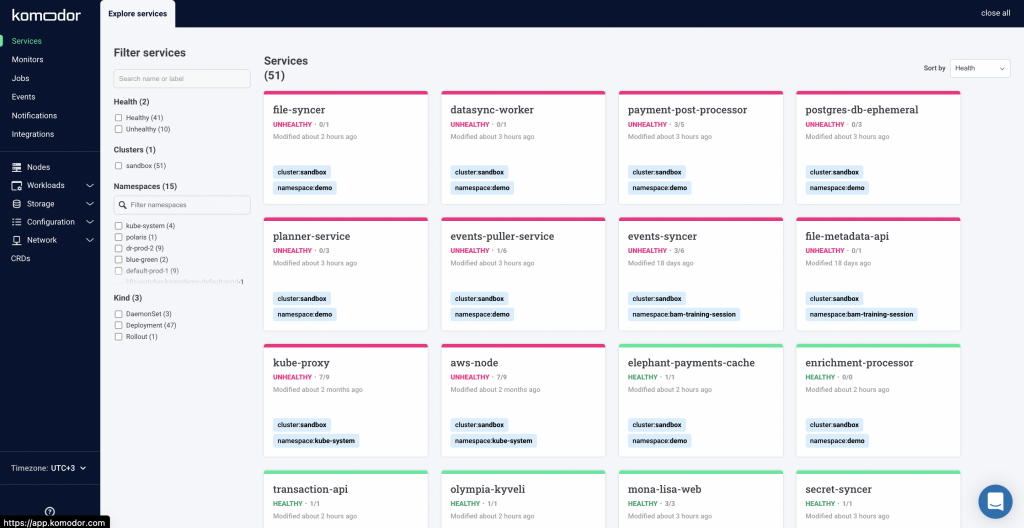
We can see that one of the services became unhealthy! Let’s dive in and see what changed. Clicking on the service reveals a complete timeline of all changes and events. On the left-hand side, you can see related services.
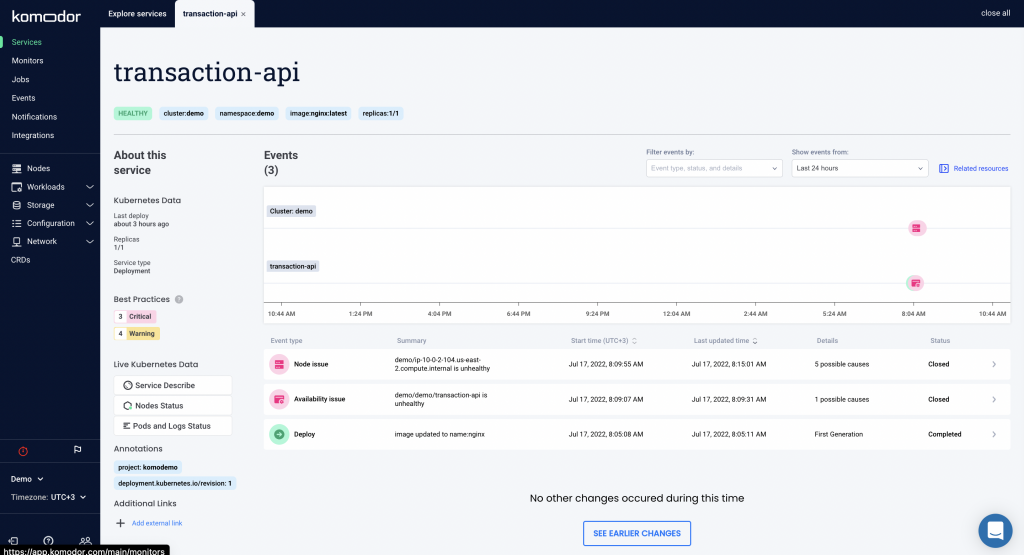
Looks like we’re having availability issues. Let’s zoom in to see exactly what happened. Clicking on any deploy or event on the timeline triggers a drawer with the Kubernetes diff, code changes, and other useful links like the corresponding build in Jenkins and dashboards in Datadog.
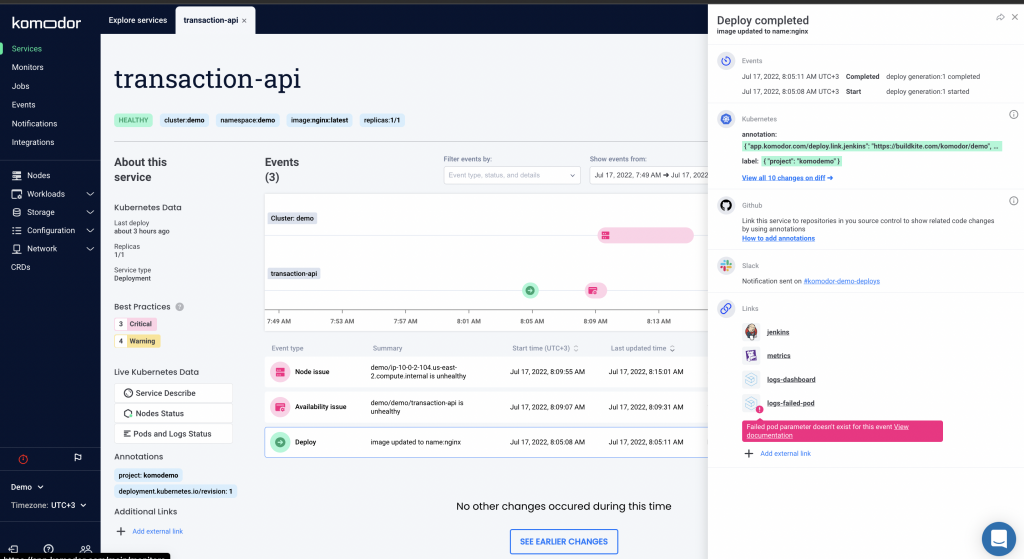
Here we can see that following the latest deploy, the app started having availability issues. Clicking on the issue prompts a drawer with all the relevant information and context you need: 2/2 of the pods are unhealthy and the service failed to fetch container logs. Plus you can see the workload description.
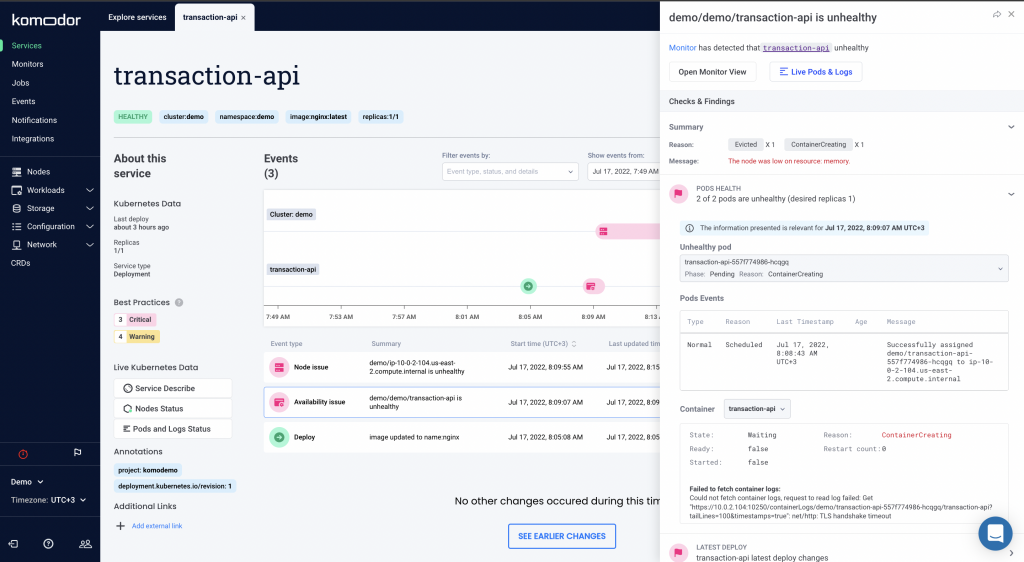
This looks a bit suspicious. Let’s have a quick look at the pod logs.
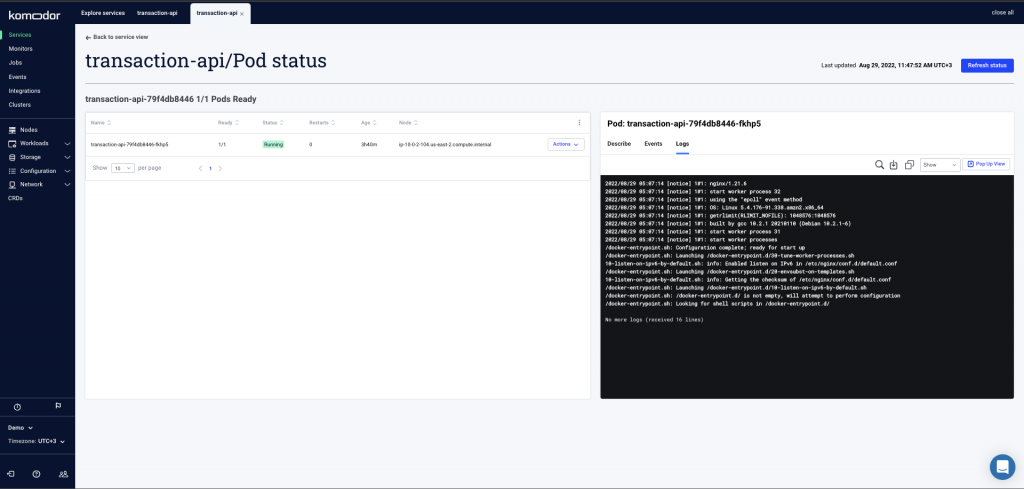
We can also see that an infra issue on the node level occurred right after the app issue. Perhaps they are correlated?
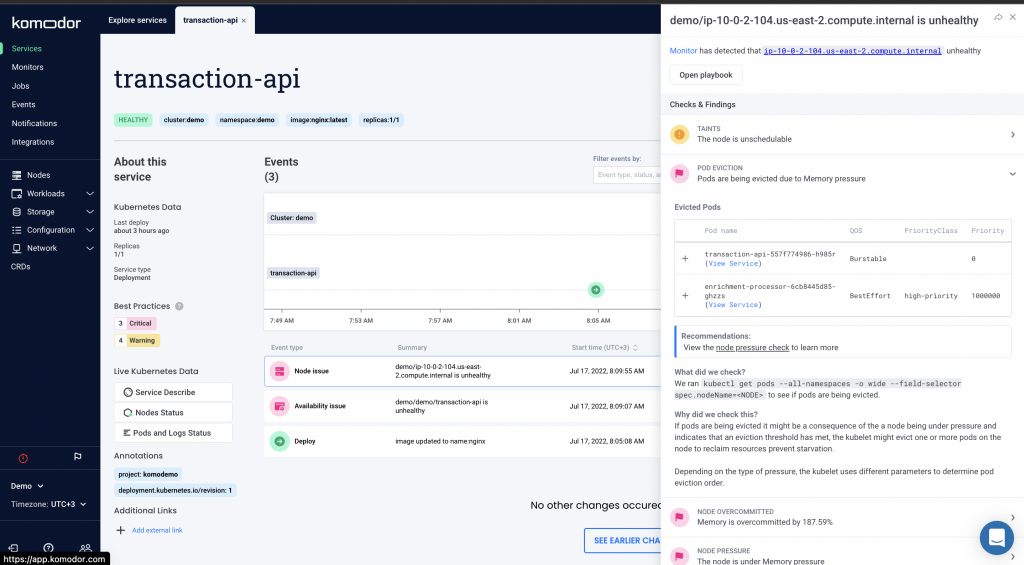
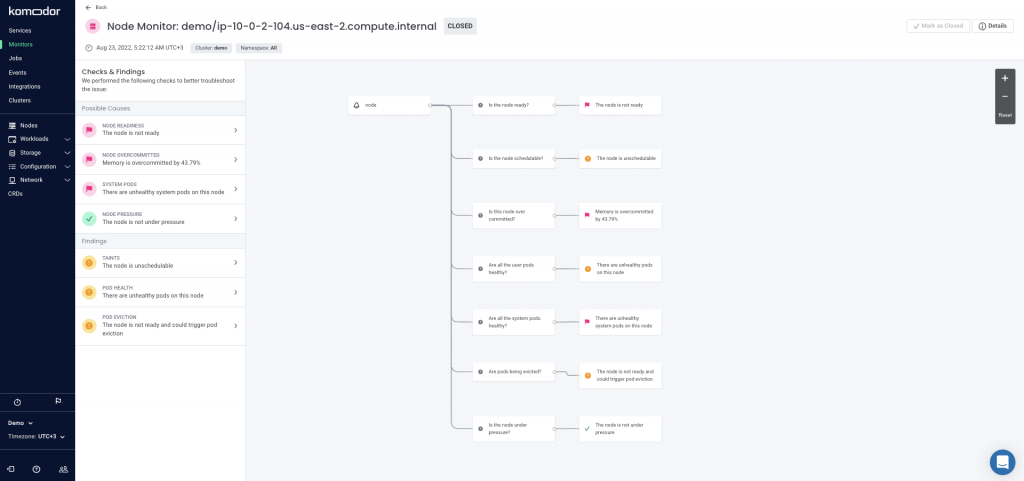
Now you would normally run a series of checks to pinpoint what’s wrong exactly with the node. Luckily for you, Komodor already ran those for you and returned with remediation instructions
You can view the full decision tree by clicking on ‘Open Playbooks’.
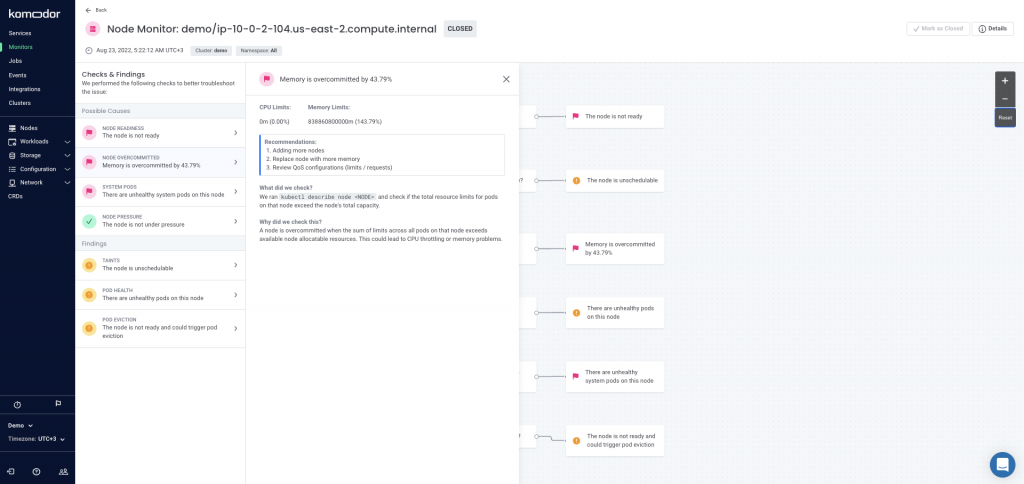
Looks like we have found the culprit! Now we can follow the instructions and configure the Quality of Service.
You can see now that the service is healthy again!
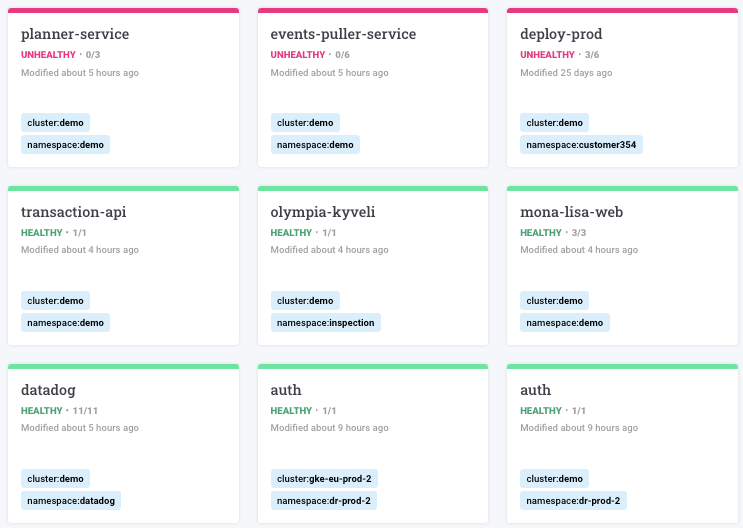
Summary
To learn more about how Komodor and SUSE Rancher can help you achieve continuous K8s reliability, visit our website for more information or get in touch with the Komodor team. You can also contact your SUSE Rancher sales representative.
We look forward to talking to you!
Author:
 Oren started out at Loom Systems (acquired by ServiceNow), then led the Customer Focus group at Check Point. He’s a fast mover and a slow cooker, with a passion for processes, procedures, R&D culture, and sous vide. Basically, he likes breaking and fixing things by understanding the big picture. Being a problem solver at heart, Oren is currently helping dev and ops teams around the world to troubleshoot Kubernetes at Komodor.
Oren started out at Loom Systems (acquired by ServiceNow), then led the Customer Focus group at Check Point. He’s a fast mover and a slow cooker, with a passion for processes, procedures, R&D culture, and sous vide. Basically, he likes breaking and fixing things by understanding the big picture. Being a problem solver at heart, Oren is currently helping dev and ops teams around the world to troubleshoot Kubernetes at Komodor.
Related Articles
Apr 21st, 2026