Backup Applications with SUSE Storage (Longhorn) V2 Volumes using Velero
Overview
When running stateful applications on Kubernetes with Longhorn as the storage provider, a common requirement is the ability to back up the entire application stack including namespaces, ConfigMaps, Secrets, PVCs/PVs. This ensure a quick and reliable restoreation if something goes wrong, even onto a new cluster.
In this guide, we’ll use Velero, a standard, open-source Kubernetes backup solution, to protect applications whose PVCs are backed by Longhorn v2 (Data Engine v2). We’ll also enable a performance optimization using Longhorn v2 linked-clone so Velero’s temporary backup PVC is created almost instantly, reducing backup time.
Longhorn v2 linked-clone feature is introduced in Longhorn v1.10 version. Please see the Github ticket for more details: https://github.com/longhorn/longhorn/issues/7794. In a nutshell, when you clone a new PVC from a PVC using linked-clone mode, there is no data copy and the clone completes instantly.
Setup SUSE Storage (Longhorn)
- Create a 3-node Kubernetes cluster.
- Install Longhorn and enable the v2 data engine following the Quick Start.
- Create a StorageClass for app PVCs (note
dataEngine: "v2"):
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-v2-data-engine
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "2"
staleReplicaTimeout: "2880"
fsType: "ext4"
dataEngine: "v2"-
Install the VolumeSnapshot CRDs and the external snapshot controller if your cluster does not have them. Refer to the
Longhorn documentation for CSI snapshot support. -
Create a
VolumeSnapshotClassfor Longhorn and label it so Velero picks it up for Longhorn-provisioned PVCs.- The label
velero.io/csi-volumesnapshot-class: "true"tells Velero to use this as the defaultVolumeSnapshotClassfor any Longhorn volumes during a backup. - The parameter
type: snapinstructs Longhorn to create an in-cluster snapshot, not a Longhorn backup. Velero will handle moving the snapshot data to the S3 bucket later.
- The label
kind: VolumeSnapshotClass
apiVersion: snapshot.storage.k8s.io/v1
metadata:
name: longhorn-snapshot-vsc
labels:
velero.io/csi-volumesnapshot-class: "true"
driver: driver.longhorn.io
deletionPolicy: Delete
parameters:
type: snapSetup Velero
- Download and install the Velero CLI from the official releases page.
-
We will use AWS S3 bucket as the backup location for Velero. Create an S3 bucket and obtain the access key and secret key. Then create a
credentials-velerofile:
[default]
aws_access_key_id=<AWS_ACCESS_KEY_ID>
aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>- Create the Velero namespace:
kubectl create ns velero- Create a fast clone StorageClass for Velero’s temporary backup PVC. We’ll use linked-clone with one replica to make the PVC creation nearly instant:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: velero-backuppvc-longhorn-v2-data-engine
provisioner: driver.longhorn.io
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "1"
staleReplicaTimeout: "2880"
fsType: "ext4"
dataEngine: "v2"
cloneMode: "linked-clone"- Tell the Velero Node Agent to use that StorageClass when it creates the temporary backup PVC:
apiVersion: v1
kind: ConfigMap
metadata:
name: velero-node-agent-cfg
namespace: velero
data:
node-agent-config.json: |
{
"backupPVC": {
"longhorn-v2-data-engine": {
"storageClass": "velero-backuppvc-longhorn-v2-data-engine"
}
}
}- Install Velero using the CLI. Include the AWS object-store plugin for S3, enable CSI, and turn on the Node Agent (privileged for block-volume access). Also pass the Node Agent ConfigMap:
velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.12.2 \ # choose a compatible version with the CLI version. Ref https://github.com/vmware-tanzu/velero-plugin-for-aws?tab=readme-ov-file#compatibility
--bucket <BUCKET> \
--backup-location-config region=<REGION> \
--secret-file ./credentials-velero \
--features=EnableCSI \ # enable CSI integration
--use-node-agent \ # required for data movement
--privileged-node-agent \ # needed for block volumes
--node-agent-configmap=velero-node-agent-cfg # needed for Longhorn linked-clone (fast clone)Deploy Application with Longhorn V2 volume
In this section, we will deploy a fully functional Gitea instance, which is a lightweight, open-source, self-hosted Git service. We’ll use a PVC backed by a Longhorn v2 volume to persist repository data. After deployment, we’ll create a sample repository, and then back up the entire application stack with Velero. We’ll use Longhorn v2’s fast clone (linked-clone) feature to significantly speed up the backup process.
Stack components:
- A dedicated namespace:
gitea-demo - A ConfigMap and a Secret for application configuration and credentials
- A Deployment for the Gitea application
- A PVC backed by a Longhorn v2 volume
- A Service to expose the application
Deploy the application
Apply the following YAML to deploy the application:
apiVersion: v1
kind: Namespace
metadata:
name: gitea-demo
---
apiVersion: v1
kind: Secret
metadata:
name: gitea-admin
namespace: gitea-demo
type: Opaque
data:
# echo -n 'admin' | base64
username: YWRtaW4=
# echo -n 'ChangeMe123!' | base64
password: Q2hhbmdlTWUxMjMh
# echo -n 'admin@example.com' | base64
email: YWRtaW5AZXhhbXBsZS5jb20=
---
apiVersion: v1
kind: ConfigMap
metadata:
name: gitea-config
namespace: gitea-demo
data:
# This file will be COPIED into the PVC by an initContainer (so Gitea can write to it later).
app.ini: |
APP_NAME = Velero Longhorn Demo
RUN_MODE = prod
RUN_USER = git
[server]
PROTOCOL = http
DOMAIN = localhost
HTTP_PORT = 3000
ROOT_URL = http://localhost:3000/
DISABLE_SSH = true
[database]
DB_TYPE = sqlite3
PATH = /data/gitea/gitea.db
[security]
INSTALL_LOCK = true
MIN_PASSWORD_LENGTH = 8
[service]
REGISTER_EMAIL_CONFIRM = false
DISABLE_REGISTRATION = true
SHOW_REGISTRATION_BUTTON = false
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: gitea-data
namespace: gitea-demo
spec:
storageClassName: longhorn-v2-data-engine
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
volumeMode: Filesystem
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: gitea
namespace: gitea-demo
spec:
replicas: 1
selector:
matchLabels:
app: gitea
template:
metadata:
labels:
app: gitea
spec:
securityContext:
runAsUser: 1000
runAsGroup: 1000
fsGroup: 1000
volumes:
- name: data
persistentVolumeClaim:
claimName: gitea-data
- name: config-src
configMap:
name: gitea-config
items:
- key: app.ini
path: app.ini
initContainers:
# 1) Seed app.ini from ConfigMap into the PVC (so it is writable/persistent)
- name: seed-config
image: docker.gitea.com/gitea:1.24.5-rootless
command: ["/bin/sh","-c"]
args:
- >
set -euo pipefail;
mkdir -p /data/gitea/conf;
if [ ! -f /data/gitea/conf/app.ini ]; then
cp /config/app.ini /data/gitea/conf/app.ini;
fi;
volumeMounts:
- name: data
mountPath: /data
- name: config-src
mountPath: /config
# 2) Create the admin user on first run (safe if rerun; it will fail if exists, which is fine)
- name: create-admin
image: docker.gitea.com/gitea:1.24.5-rootless
env:
- name: USERNAME
valueFrom:
secretKeyRef:
name: gitea-admin
key: username
- name: PASSWORD
valueFrom:
secretKeyRef:
name: gitea-admin
key: password
- name: EMAIL
valueFrom:
secretKeyRef:
name: gitea-admin
key: email
command: ["/bin/sh","-c"]
args:
- >
set -e;
/usr/local/bin/gitea migrate --config /data/gitea/conf/app.ini;
/usr/local/bin/gitea admin user create
--admin --username "$USERNAME" --password "$PASSWORD" --email "$EMAIL"
--config /data/gitea/conf/app.ini || echo "admin may already exist";
volumeMounts:
- name: data
mountPath: /data
containers:
- name: gitea
image: docker.gitea.com/gitea:1.24.5-rootless
ports:
- name: http
containerPort: 3000
env:
# Tell Gitea where the persistent data is
- name: GITEA_WORK_DIR
value: /data
- name: GITEA_APP_INI
value: /data/gitea/conf/app.ini
volumeMounts:
- name: data
mountPath: /data
---
apiVersion: v1
kind: Service
metadata:
name: gitea
namespace: gitea-demo
spec:
selector:
app: gitea
ports:
- name: http
port: 3000
targetPort: 3000
type: ClusterIPGenerate some data
- Port forward the application to localhost:
kubectl -n gitea-demo port-forward svc/gitea 3000:3000 - Go to
http://localhost:3000/to access Gitea - Login with username
adminand passwordChangeMe123! - Create a hello-world git repo and write some data to its
README.mdfile - Clone the hello-world repo:
git clone http://localhost:3000/admin/hello-world.git - Add an OS image of around 1 GiB, commit, and push it
- The outcome should look like this:
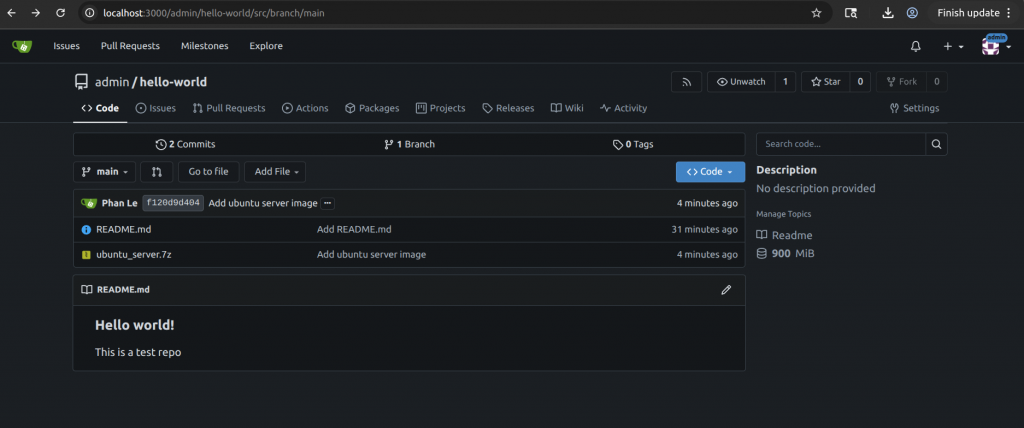
Backup
We’ll back up the entire application stack and the PVC data using CSI Snapshot Data Movement.
How it works under the hood:
- Velero creates a CSI snapshot of the PVC.
- Velero creates a temporary backup PVC from that snapshot.
- A data-mover pod mounts the backup PVC (read-only) and uploads the data to S3.
Because we configured the Node Agent to use a linked-clone StorageClass, step 2 is near-instant.
Run this command to create the backup:
velero backup create gitea-bkp \
--include-namespaces gitea-demo \
--snapshot-move-data \
--waitObserve that the cloning happens very fast. Uploading to S3 might take some time.
Once successful, you should see:
➜ ~ velero backup get
NAME STATUS ERRORS WARNINGS CREATED EXPIRES STORAGE LOCATION SELECTOR
gitea-bkp Completed 0 0 2025-09-03 19:56:14 -0700 PDT 29d default <none>Restore
- To simulate a disaster case, delete the Gitea namespace so that the application stack is destroyed:
kubectl delete ns gitea-demo- Restore the entire application stack:
velero restore create gitea-restore --from-backup gitea-bkp --wait- Wait for the restoration to finish.
- Port forward the application to localhost:
kubectl -n gitea-demo port-forward svc/gitea 3000:3000- Go to
http://localhost:3000/to access Gitea. - Login with username
adminand passwordChangeMe123!. - Verify that you see the same
README.mdfile and the Ubuntu server image.
Restore to different cluster and different storage provider
One very useful feature of Velero is the ability to restore the PVC data into a PVC provisioned by a different storage provider. This allows you to migrate data to a different cluster and a different storage provider.
- Install Velero on the target cluster and point it to the same S3 bucket.
- Map your source StorageClass → target StorageClass with this ConfigMap (in the
veleronamespace):
apiVersion: v1
kind: ConfigMap
metadata:
# any name can be used; Velero uses the labels (below)
# to identify it rather than the name
name: change-storage-class-config
# must be in the velero namespace
namespace: velero
# the below labels should be used verbatim in your
# ConfigMap.
labels:
# this value-less label identifies the ConfigMap as
# config for a plugin (i.e. the built-in restore item action plugin)
velero.io/plugin-config: ""
# this label identifies the name and kind of plugin
# that this ConfigMap is for.
velero.io/change-storage-class: RestoreItemAction
data:
# add 1+ key-value pairs here, where the key is the old
# storage class name and the value is the new storage
# class name.
longhorn-v2-data-engine: local-pathIn this example, PVCs that originally used longhorn-v2-data-engine will be restored using local-path on the destination cluster.
Conclusion
You have now built an end-to-end application-aware backup and restore workflow for a Longhorn v2–backed workload using Velero + CSI Snapshot Data Movement. This solution provides several key benefits:
- Fast backups thanks to linked-clone for the temporary backup PVC.
- Portable, deduplicated data in S3 for cross-cluster disaster recovery.
- Flexible restores — including remapping to a different StorageClass on a different cluster.
From here, consider adding scheduled backups with TTLs, namespace label selectors for fine-grained protection, and pre/post hooks for quiescing databases.
Related Articles
Feb 25th, 2026