Persistent Block Storage for Kubernetes: SUSE Storage, powered by Longhorn

This article was written by Sushant Gaurav, Technical Engineer Writer at the SUSE Documentation Team.
When you run applications on Kubernetes, you need persistent storage. This storage retains data even if a pod restarts, crashes, or reschedules to another node. Kubernetes manages this through Persistent Volumes (PVs) and Persistent Volume Claims (PVCs), which allow applications to request and use storage resources.
But where does this storage come from? A Storage Provisioner handles this by dynamically creating and managing the actual storage that backs these PVCs.
What is Longhorn: The foundation of SUSE Storage
SUSE Storage provides a lightweight, reliable, and powerful distributed block storage system for Kubernetes. It is built entirely on Longhorn, the cloud native, Kubernetes-specific open source project that serves as its core technology.
So what makes it stand out? Let’s break down its key characteristics:
- Lightweight: Longhorn is resource-efficient and easy to deploy, eliminating the need for heavyweight storage stacks.
- Cloud native: It integrates deeply with Kubernetes, utilizing its APIs and concepts like Custom Resource Definitions (CRDs) and controllers.
- Distributed: Longhorn replicates data across multiple nodes to provide high availability and prevent data loss.
- Block Storage: Longhorn provides volumes as block devices, similar to hard drives or SSDs. This makes it ideal for databases, file systems, and stateful applications.
- Seamless Kubernetes Integration: It acts as a dynamic provisioner using Kubernetes StorageClass, which automates and declares persistent storage management.
But let’s dive even deeper!
Understanding Block Storage
First, let’s focus on block storage: it divides data into fixed-sized “blocks”, each with a unique identifier. This method allows systems to retrieve or modify individual blocks independently. Unlike file storage, block storage does not manage data with a file-and-folder hierarchy. This characteristic makes block storage fast, flexible, and ideal for performance-critical workloads such as databases, virtual machines, transactional systems, and Kubernetes persistent volumes.
Understanding its working
Now, let me detail how this works. Imagine each Kubernetes worker node has local disk space. Longhorn pools this local storage across all nodes. When a pod requests a persistent volume:
- Longhorn carves out a volume from the storage pool.
- It replicates that volume across multiple nodes for data safety.
- It then exposes the volume to the pod as a block device, ready for mounting and use.
Behind the scenes, Longhorn uses Kubernetes primitives and its own controller logic to automatically maintain, recover, and manage volumes.
Why Use Longhorn?
Kubernetes enables container orchestration at scale, but it does not include built-in persistent storage. Longhorn fills this gap, offering a robust, cloud native solution for managing stateful workloads. Here’s why Longhorn is a valuable addition to your Kubernetes environment:
Data Persistence
Most importantly, Longhorn ensures your data survives pod restarts, rescheduling, and even node failures. This provides stateful applications the reliability they need to function in dynamic environments.
High Availability
Keep in mind that every Longhorn volume is replicated across multiple nodes. Even if a node or disk fails, your application continues to function without data loss. This replication makes Longhorn ideal for production-grade databases, message queues, and other critical workloads.
Ease of Use
In addition, Longhorn includes a clean and intuitive web-based user interface (UI), simplifying storage operations such as creating volumes, snapshots, or backups. It also integrates deeply with Kubernetes, using native APIs and Custom Resource Definitions (CRDs), allowing for declarative management.
Advanced Features
Longhorn provides the following capabilities out-of-the-box:
- Snapshots for point-in-time recovery
- Backups to S3 or NFS-compatible targets
- Live volume migration across nodes
- Incremental backups and restores
- Metrics and monitoring via Prometheus
Cost-Effective
Longhorn uses the existing local storage on your Kubernetes nodes. This reduces your dependency on expensive cloud storage services like AWS EBS or GCP Persistent Disks. In consequens, this makes Longhorn a compelling solution for on-premises, edge, and hybrid cloud deployments.
Core Concepts of Longhorn
To understand how Longhorn works behind the scenes, you should become familiar with its foundational concepts. These are the essential building blocks of how Longhorn delivers reliable, high-performance storage within a Kubernetes cluster. Let’s explore each concept.
Volume
At its core, Longhorn uses a volume which is a virtual storage device, similar to a hard disk or solid-state drive (SSD) in a traditional setup. When you create a Longhorn volume, you specify its size and the number of replicas it should maintain. Behind the scenes, Longhorn automatically provisions a Kubernetes PersistentVolume (PV) that your applications can consume through PersistentVolumeClaims (PVCs). This abstraction enables applications to use reliable storage without needing to know where or how the data is physically stored.
Replica
Every Longhorn volume is backed by one or more replicas which has exact, real-time copies of the volume’s data. These replicas distribute across different nodes in your Kubernetes cluster to ensure high availability and fault tolerance. If a node fails, Longhorn keeps your application running by redirecting storage access to healthy replicas on other nodes. Most production setups use two or three replicas per volume, balancing durability and resource usage.
Engine
Each active Longhorn volume is managed by a dedicated Longhorn Engine process. This engine acts as the volume’s control plane, orchestrating all read and write operations and ensuring data consistency across all replicas. An important design choice is that the engine always runs on the same node as the application pod that uses the volume. This local placement reduces latency and improves performance by keeping input-output (I/O) traffic close to the workload.
Disk
In Longhorn, a disk refers to a specific directory path on a node’s local storage that Longhorn is permitted to use. For example, you might configure /var/lib/longhorn/ as a usable disk location. By managing these disk paths, Longhorn allocates storage, balances replica placement, and monitors available capacity while adhering to your defined constraints.
Node
A node in Longhorn is simply a Kubernetes worker that is configured to run Longhorn components. These nodes host data (via replicas), perform I/O operations (via engines), and manage resources (via instance managers). To ensure data resilience, Longhorn distributes replicas of the same volume across different nodes. Your volume therefore remains accessible even if a machine goes offline.
Instance Manager
Behind the scenes, Longhorn runs an Instance Manager pod on every storage-enabled node. This component acts as a supervisor, responsible for starting, stopping, and monitoring the engines and replicas on that node. There are typically two instance managers per node, one for managing engines and one for replicas. But they share the same goal which is to keep the storage layer healthy and responsive.
Snapshot
A snapshot in Longhorn is a point-in-time copy of a volume’s data. It is highly efficient because Longhorn creates incremental snapshots, which only track changes since the last one. This makes snapshots a powerful tool for quick recovery. If you accidentally delete a file or misconfigure your database, you can simply revert the volume to a previous snapshot and restore it within seconds.
Backup
While snapshots are stored locally, backups extend this by copying those snapshots to external storage such as an S3-compatible object store (for example, AWS S3, MinIO) or an NFS server. Backups are critical for disaster recovery. If your entire cluster fails, you can rebuild your volumes from backup data stored securely outside the cluster.
StorageClass
Longhorn integrates seamlessly with Kubernetes by exposing a custom StorageClass (typically named longhorn). When your application defines a PVC using this StorageClass, Longhorn automatically provisions a new volume with the specified configuration, including size, replica count, and more. This tight integration allows developers and platform engineers to request reliable storage declaratively using native Kubernetes YAML files.
Putting It All Together
Now, let’s tie all these concepts into one clear picture. Imagine your application requires 10 GB of persistent storage. You create a PVC specifying 10 GB and using the longhorn StorageClass. Longhorn receives this request and:
- Creates a 10 GB volume.
- Provisions three replicas across three different Kubernetes nodes.
- Launches an engine on the same node as your application pod.
- Handles input-output from the pod, syncing data across all replicas.
- Allows you to take snapshots periodically.
- Sends backups of those snapshots to an S3 bucket for disaster recovery.
How Longhorn Works
Longhorn fundamentally comprises a coordinated system of controllers, managers, and data planes. Let’s walk through the lifecycle of a volume right from the moment your application requests storage, to how that data is stored, replicated, and protected.
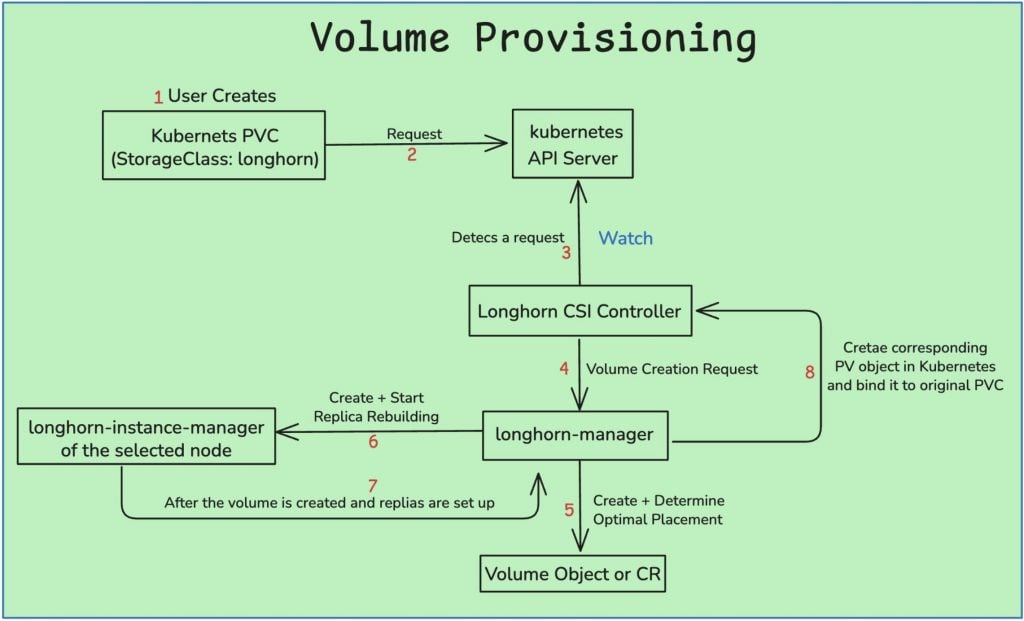
1. Volume Provisioning
The process begins when your application requires persistent storage:
-
A Developer Creates a PVC The developer (or Helm chart, or operator) defines a PersistentVolumeClaim (PVC), for example, requesting
10Giusing thelonghornStorageClass. -
Kubernetes API Receives the Request The Kubernetes API server receives this PVC and holds it until a matching volume can be provisioned.
-
Longhorn CSI Controller Steps In The
longhorn-csi-pluginrunning in your cluster detects the PVC and forwards the request to the Longhorn Manager. -
Volume Planning by Longhorn Manager The manager creates a new internal Longhorn
Volumeobject. It determines:- How many replicas to create
- Which nodes and disks should host them
- Ensures anti-affinity rules so that replicas do not reside on the same node
-
Replica Deployment via Instance Managers The manager communicates with
instance-managerpods on chosen nodes to initiatelonghorn-replicaprocesses. Each process allocates space on its local disk. -
PersistentVolume is Created Once all components are ready, the manager notifies the CSI controller, which creates a Kubernetes
PersistentVolume(PV) and binds it to your original PVC.
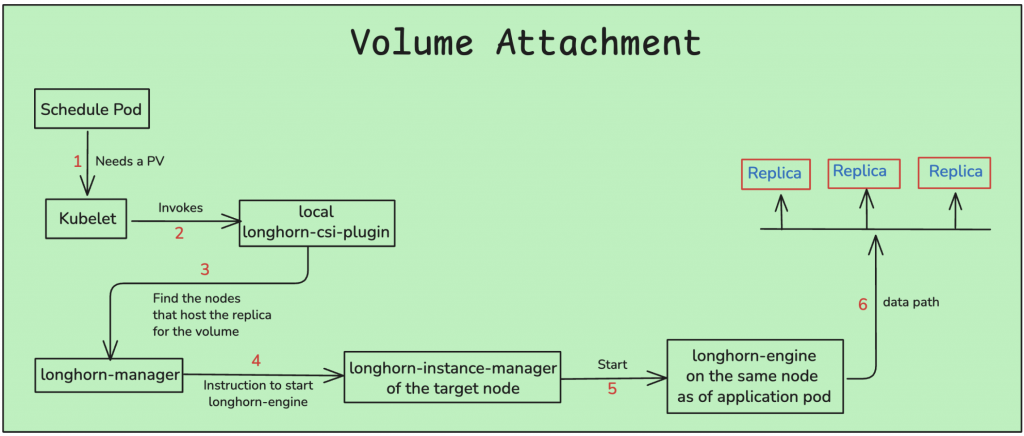
2. Volume Attachment
Now that the volume exists, it is connected to your application pod:
-
Pod is Scheduled Kubernetes schedules your pod (for example, a database) on a node. Kubernetes is aware that the pod needs the volume.
-
CSI Node Plugin Engages The
longhorn-csi-pluginrunning on the node (as a DaemonSet) receives a callback from the kubelet to handle attachment. -
Engine is Started The CSI plugin contacts the Longhorn Manager, which initiates a dedicated
longhorn-engineprocess on the same node as the pod. -
Engine Connects to Replicas This engine connects with all the distributed replica processes to establish a data path and ensure everything is synchronized.
-
Volume is Mounted Finally, the block device is exposed to the host and mounted into your container. Your application now recognizes a volume and can begin reading from or writing to it—as if it were a regular disk.
3. Data Input-Output (I/O)
Once mounted, the primary operations begin:
-
All Writes Go Through the Engine Every write from the application is first handled by the
longhorn-engine, which synchronously replicates the data to all replicas. -
Write Quorum Ensures Safety Longhorn waits for a quorum (majority) of replicas to acknowledge the write before confirming success to the application. This guarantees strong consistency.
-
Reads Are Optimized For reads, the engine often retrieves data from the nearest healthy replica, which reduces latency and improves performance.
The engine serves as the real-time coordinator that keeps replicas synchronized, ensures durability, and handles any failovers if an issue occurs.
4. Data Protection (Snapshots and Backups)
Longhorn simplifies protecting your volumes with point-in-time recovery and off-cluster backups:
-
Snapshots (Instant, Local) Snapshots capture the exact state of a volume at a specific point in time. They are incremental and stored within the volume’s replicas, making them fast and efficient.
-
Backups (Off-Cluster, Durable) Snapshots can be exported to remote storage (such as S3, MinIO, or NFS) as backups. The manager handles this asynchronously, so it does not block your application’s I/O.
These features are ideal for disaster recovery, version rollback, and long-term archival.
5. Failure Recovery
Failures can occur. Longhorn is designed to recover automatically:
-
Replica Failures: If a replica or the node it resides on fails, Longhorn detects the failure. As long as a quorum of healthy replicas remains, the volume continues to function. Longhorn then identifies another healthy node, initiates a new replica, and rebuilds it by streaming data from the surviving replicas.
-
Engine Failures (Pod Node Crashes): If the pod and engine’s node fails,
- Kubernetes reschedules the pod to a new node.
- Longhorn detects the failed engine and launches a new one on the new node.
- The new engine reconnects to the healthy replicas and resumes operations.
This self-healing mechanism ensures minimal downtime and no data loss.
6. Detachment and Deletion
When your application no longer needs the volume:
- Kubernetes deletes the pod or PVC.
- The CSI plugin unmounts and detaches the volume.
- The engine is stopped.
- If the volume is deleted, all replicas and metadata are removed from the cluster.
Longhorn Volume Lifecycle
To better understand how Longhorn manages volumes, just have a look at the following diagrams. They illustrate the end-to-end lifecycle, from provisioning the volume to attaching it to a running application pod.
Volume Provisioning
Volume Attachment
Key Features of Longhorn
Longhorn provides more than just persistent volumes in Kubernetes. It is a full-fledged, enterprise-grade storage solution purpose-built for cloud native environments. Let’s explore the key features that distinguish Longhorn from traditional storage tools.
Enterprise-Grade Distributed Block Storage
At its core, Longhorn delivers distributed block storage, meaning your data is spread across multiple nodes within the cluster. This offers several critical advantages:
- High Availability: Longhorn maintains multiple replicas of your volume, ensuring data availability even if a node fails. It also performs automatic failover and healing, which provides uninterrupted storage access.
- Fault Tolerance: Longhorn is designed to gracefully handle failures, whether from a node crash, disk failure, or network disruption.
This level of redundancy and resilience is characteristic of a top-tier storage system, and Longhorn provides it natively within Kubernetes.
Incremental Snapshots
Snapshots are essential for data protection, and Longhorn implements them efficiently:
- Space-Efficient: Only the changes since the last snapshot are stored, making them lightweight and scalable.
- Point-in-Time Recovery: If data is accidentally deleted or an application misbehaves, you can instantly roll back to a previous snapshot.
- System-Generated Snapshots: During critical operations, such as replica rebuilding, Longhorn automatically generates snapshots to maintain consistency.
Cross-Cluster Backups (S3/NFS)
Longhorn supports cross-cluster backups to external storage systems like S3 or NFS. This is a significant advantage for disaster recovery and compliance:
- Disaster Recovery: Back up your volumes to S3-compatible storage (for example, AWS S3, MinIO, GCS) or network file systems.
- Long-Term Archival: This feature is ideal for retaining historical data for audits or regulatory requirements.
- Easy Restoration: Volumes can be restored to the same or a different cluster, offering genuine disaster recovery capabilities.
Recurring Snapshots and Backups
You do not need to manually manage data backups; Longhorn automates this process.
- Automated Scheduling: Set up recurring snapshots and backups directly from the Longhorn UI or through Kubernetes manifests.
- Retention Policies: Control the number of snapshots or backups to retain, ensuring storage efficiency without compromising safety.
Intuitive Graphical User Interface (GUI) for Management
Managing storage does not need to be limited to the command line. Longhorn includes a clean, Web-based dashboard that provides comprehensive control.
- Visual Oversight: View the real-time health of nodes, disks, volumes, and replicas.
- One-Click Actions: Perform operations such as attaching, detaching, creating, snapshotting, backing up, and restoring directly from the browser.
ReadWriteMany (RWX) Support via NFS
While traditional block storage in Kubernetes typically supports only ReadWriteOnce (RWO), Longhorn can enable RWX mode:
- Shared Access: Multiple pods can read from and write to the same volume. This is ideal for shared Content Management Systems (CMS) or file-based applications.
- Built-In NFS Server: Longhorn uses a
longhorn-share-managercomponent to expose volumes over NFS internally.
Live Volume Migration
If you need to perform maintenance on a node or rebalance workloads:
- Non-Disruptive Migration: Move a running volume with its application still writing data—from one node to another without downtime.
Automated, Non-Disruptive Upgrades
Upgrading storage systems can be risky, but not with Longhorn:
- Rolling Upgrades: Longhorn allows you to update its components (engine, manager, replicas) without affecting running workloads.
Multi-Disk Support on Nodes
If your nodes have multiple disks (such as SSDs or HDDs), Longhorn can utilize all of them.
- Tiered Storage: Assign tags to disks and nodes for intelligent placement of replicas. For example, place performance-critical data on SSDs and backups on HDDs.
Volume Encryption
Security is integrated:
- At-Rest Encryption: Longhorn encrypts data using Linux’s
dm-cryptand securely manages keys via Kubernetes Secrets.
Online Volume Expansion
If you need more storage space, you do not need to delete or recreate anything.
- Live Resizing: Increase your volume size on the fly without stopping the application or unmounting the volume.
When to Use Longhorn
Longhorn excels in cloud native environments where simplicity, resilience, and cost-efficiency are paramount. Let’s explore the scenarios where Longhorn is not merely a viable option, but the ideal choice.
Edge Deployments and Distributed Environments
In edge computing, traditional centralized storage solutions (such as Storage Area Networks [SAN] or Network Attached Storage [NAS]) are often impractical due to cost, complexity, or infrastructure limitations. Longhorn extends powerful storage capabilities to the edge by utilizing the local disks of your Kubernetes nodes.
Where it is used:
- Retail stores
- Factory automation
- Telecom base stations
- Internet of Things (IoT) data collection at the edge
- Remote branch offices
In these environments, Longhorn transforms basic compute nodes into highly available, self-healing storage nodes, eliminating the need for external storage infrastructure.
Small to Medium-Sized Kubernetes Clusters
Not every Kubernetes cluster requires the capacity or expense of enterprise-grade storage arrays. Longhorn is easy to deploy and manage, making it suitable for internal platforms and general-purpose workloads.
Where it is used:
- Internal Continuous Integration and Continuous Delivery (CI/CD) pipelines
- Business applications (Customer Relationship Management [CRM], Enterprise Resource Planning [ERP])
- Development and staging environments
- Self-hosted services like GitLab, Jenkins, or databases
Longhorn enables smaller teams to maintain agility without sacrificing data persistence or reliability.
Cost-Effective Storage in the Cloud
Cloud block storage is powerful, but it can be expensive. Longhorn reduces costs by utilizing the storage already present on your Kubernetes nodes, allowing you to reserve cloud provider-managed block storage for only the most critical volumes.
Where it is used:
- cloud native workloads optimized for cost efficiency
- Stateful services running on spot instances
- Applications with moderate input/output (I/O) needs but strong durability requirements
This approach is particularly beneficial when managing large-scale applications where the cost of each persistent volume accumulates.
Applications Requiring High Availability and Durability
Longhorn synchronously replicates data across nodes, ensuring high availability and consistency. Even if a node or disk fails, your application remains online with minimal disruption due to automated healing.
Where it is used:
- Databases (PostgreSQL, MySQL, MongoDB)
- Queuing systems (Kafka, RabbitMQ)
- Stateful microservices
- In-memory data stores and distributed caches
It provides production-grade resilience without the overhead of complex traditional storage.
Simplified Storage Management for Platform Engineers
Longhorn was designed with Kubernetes operators in mind. Its intuitive user interface (UI) and tight Container Storage Interface (CSI) integration offer seamless volume provisioning, snapshot management, and backup scheduling—all managed within Kubernetes.
Where it is used:
- Internal developer platforms
- Infrastructure teams managing storage-as-a-service
- Teams with limited storage expertise but significant reliability objectives
Longhorn eliminates the need to manage external storage tools or Application Programming Interfaces (APIs), allowing platform teams to focus on their core responsibilities.
Development and Testing Environments
Developers frequently require lightweight, reproducible environments with persistent storage. Longhorn functions effectively in local or minimal clusters like K3s or Minikube, and it supports features such as snapshotting and volume cloning out-of-the-box.
Where it is used:
- Local development clusters
- CI/CD testing pipelines
- Application prototyping and Quality Assurance (QA)
It assists development teams in testing stateful workloads without incurring the expense of external storage.
Workloads Requiring Snapshots and Backup
Whether you are preparing for disaster recovery or simply need consistent backup routines, Longhorn provides snapshot and backup support to external systems like S3 and NFS.
Where it is used:
- Critical data platforms
- Applications with regular versioning needs
- Any environment where data loss is not an option
Snapshots and backups can be automated, providing peace of mind with minimal manual effort.
Architecture Overview
At its core, Longhorn transforms the local storage of your Kubernetes worker nodes into a reliable, high-availability storage layer, while remaining lightweight and Kubernetes-native.
Control Plane Versus Data Plane: The Core Design
One of Longhorn’s key design philosophies is the separation of the control plane and data plane:
- Control Plane: Orchestrates storage logic, such as determining where volumes and replicas should run, and managing metadata, snapshots, and backups.
- Data Plane: Performs the intensive tasks of actual data replication and input/output (I/O) on each node.
Control Plane Components
These components typically run as Kubernetes Deployments and are responsible for managing the state and behavior of volumes.
- Longhorn Manager: This is the central coordinating component for volumes, replicas, and storage actions.
- CSI Controller Plugin: This component interfaces with Kubernetes to fulfill volume provisioning requests.
- Longhorn UI: This is a web-based dashboard used to visualize and manage your volumes.
These components operate in close coordination with the Kubernetes API server to ensure volumes are optimally placed and managed.
Data Plane Components
These components run closer to the actual workload and typically exist on each worker node as DaemonSets or Pods.
- Instance Manager: This component acts as a node-local supervisor. It manages the lifecycle of Engines and Replicas on its respective node.
- CSI Node Plugin: This plugin mounts Longhorn volumes to your pods by interfacing with the kubelet.
- Longhorn Engine: This component serves data directly to your application and is always co-located with the application pod to ensure low latency.
- Longhorn Replica: These components are the actual data holders, storing the blocks on disk. Multiple replicas distribute across nodes for high availability.
Note: If a node crashes, Longhorn quickly rebuilds replicas on other healthy nodes, ensuring your data remains safe and accessible.
Data Flow
When your application writes to a Longhorn volume:
- The Engine on the same node receives the I/O request.
- It then synchronously replicates the data to other replicas across the network.
- This process ensures real-time redundancy with minimal latency.
External Backup Support
Longhorn extends beyond replication by supporting off-cluster backups. You can push backups to:
- Amazon S3
- NFS shares
Managing Longhorn with Longhorn UI, kubectl, and API
When working with Longhorn in Kubernetes, understanding how to manage and interact with it is as important as knowing its underlying mechanisms. Whether you are a platform engineer exploring Longhorn for the first time or delving into its codebase, you will benefit from knowing the different interfaces available for management.
Longhorn provides four primary methods to manage your storage setup: the Longhorn UI, kubectl, the Longhorn API, and Helm for installation and upgrades.
1. Longhorn UI
It is the most intuitive entry point for managing your Longhorn environment. It provides a comprehensive overview of your storage state and actionable controls, all within a browser-based dashboard.
Capabilities of the UI:
- Volume Management: Create, delete, attach, and detach volumes. Monitor volume health, performance metrics, and input-output (I/O) activity.
- Node Management: View available nodes, their disk capacity, and enable or disable volume scheduling per node.
- Disk Management: Define which disk paths Longhorn can use, add or remove disks, and configure disk tags.
- Snapshots and Backups: Manually or automatically take snapshots, back them up, and restore volumes as needed.
- Recurring Jobs: Schedule recurring snapshots and backups to maintain data protection policies.
- Monitoring and Charts: Gain visual insights into volume throughput, latency, and operations. For advanced monitoring, integrate with Prometheus or Grafana.
- Settings: Adjust global settings such as backup targets and replica balancing policies.
Accessing the UI: You can access the UI through a Kubernetes Ingress, a NodePort service, or by using
kubectl port-forwardon thelonghorn-uiservice.
2. Managing Longhorn with kubectl
Longhorn is deeply integrated into Kubernetes using Custom Resource Definitions (CRDs). This means you can use standard Kubernetes tooling like kubectl to control Longhorn objects, which is ideal for scripting, GitOps, and automation workflows.
Common Longhorn CRDs:
volumes.longhorn.ionodes.longhorn.ioreplicas.longhorn.iobackups.longhorn.iosettings.longhorn.io
Behind the scenes, the longhorn-manager acts as a Kubernetes controller that continuously reconciles the desired state (CRDs) with the actual state in the cluster.
3. Programmatic Control via Longhorn API
For advanced users or teams developing custom tooling, the Longhorn API offers programmatic access to nearly every function exposed by the Longhorn UI.
- RESTful API: This is the same API used by the UI, enabling you to automate or extend Longhorn’s capabilities.
- OpenAPI/Swagger Documentation: The API is fully documented, making it easy to explore or generate Software Development Kits (SDKs).
- Integration Possibilities: Integrate Longhorn into your internal dashboards, monitoring systems, or provisioning workflows.
Access Point: The API is served via the
longhorn-managerpods and is typically exposed through a Kubernetes service within the cluster.
4. Helm
Although Helm does not manage daily volume or node operations, it serves as the standard method for installing and upgrading Longhorn in your Kubernetes cluster.
- Deploy Longhorn using the official Helm chart.
- Configure global settings during installation (for example, replica count, backup targets).
- Easily upgrade versions or roll back if necessary.
Installation
You can install Longhorn in your Kubernetes cluster using a straightforward process. Choose from several deployment methods to accommodate your specific environment and operational preferences. Before you begin with any installation method, however, ensure your cluster meets the following recommended prerequisites:
- A Kubernetes cluster (version 1.25 or newer is recommended, please refer to the official documentation for compatibility with your specific Longhorn version).
- A compatible Container Storage Interface (CSI) and iSCSI setup on all nodes. This typically requires
open-iscsi(oriscsidfor some distributions) and privilege support on the nodes. - Adequate local disk space on your nodes for volume replicas.
For detailed, step-by-step instructions, specific customizations, and comprehensive upgrade guidance, always refer to the official Longhorn documentation.
You can deploy Longhorn using the following methods:
-
Install as a Rancher Apps & Marketplace: If you are using Rancher, Longhorn can be easily deployed through its integrated Applications & Marketplace (refer to the official guide for Rancher Apps & Marketplace installation).
-
Install with Kubectl: For direct deployment using Kubernetes manifest files (refer to the official guide for Kubectl installation).
-
Install with Helm: The recommended and most common method for deploying Longhorn (refer to the official guide for Helm installation).
-
Install with Helm Controller: For automated deployment and management of Helm charts within Kubernetes (refer to the official guide for Helm Controller installation).
-
Install with Fleet: For GitOps-driven deployment across multiple clusters using Fleet (refer to the official guide for Fleet installation).
-
Install with Flux: For GitOps-driven deployment using Flux CD (refer to the official guide for Flux installation).
-
Install with ArgoCD: For GitOps-driven deployment using ArgoCD (refer to the official guide for ArgoCD installation).
-
Air Gap Installation: For deploying Longhorn in air-gapped environments without direct internet access (refer to the official guide for Air Gap installation).
Frequently Asked Questions (FAQs)
1. What is the Container Storage Interface (CSI), and why is it important for Longhorn?
The Container Storage Interface (CSI) is a standardized interface that enables storage vendors to develop plugins that operate seamlessly across container orchestrators like Kubernetes. Longhorn implements a CSI driver that integrates directly with Kubernetes’ native storage primitives, such as Persistent Volumes (PVs), Persistent Volume Claims (PVCs), and StorageClasses. This integration means you do not have to modify Kubernetes to enable Longhorn. CSI decouples storage development from Kubernetes itself, making Longhorn more modular and resilient to future changes.
2. What is CSIProxy?
CSIProxy is a specialized tool designed for Windows-based Kubernetes environments. Because Windows containers cannot directly perform privileged operations on the host (unlike Linux), CSIProxy bridges that gap. It runs as a native Windows service and allows CSI Node Plugins—like Longhorn’s—to manage storage tasks such as mounting and formatting volumes, thereby enabling Longhorn to function effectively with Windows nodes.
3. How does Longhorn provide high availability?
Longhorn is built with resilience and redundancy as core principles:
- Synchronous Replication: Each volume has multiple replicas distributed across different nodes. Writes are synchronized in real-time to ensure no data loss during node failures.
- Automated Engine Failover: If the node hosting a pod and its volume engine fails, Kubernetes reschedules the pod elsewhere. Longhorn detects this failure and restarts the engine on the new node using healthy replicas.
- Automatic Replica Rebuilds: When a replica or its host goes offline, Longhorn automatically creates a new replica on a healthy node by copying data from the remaining healthy ones.
4. What is SPDK, and how does it relate to Longhorn?
The Storage Performance Development Kit (SPDK) is a collection of high-performance, user-space storage libraries that bypass the Linux kernel’s input-output (I/O) stack. This results in significantly lower latency and higher throughput, especially for NVMe-based storage.
Longhorn supports an advanced V2 Data Engine built on SPDK; find more details here. This is ideal for workloads requiring ultra-low-latency and high IOPS, such as real-time analytics or databases.
5. What are the key benefits of using SPDK?
SPDK provides several performance enhancements:
- Ultra-high IOPS and throughput
- Minimal I/O latency
- Lower CPU utilization per I/O operation
- Hardware-agnostic via its block device layer (BDEV)
- Modular design for constructing custom storage stacks
For modern cloud native applications, these benefits translate into faster response times and improved efficiency.
6. How does Longhorn handle data protection?
Longhorn provides built-in backup and snapshot capabilities:
- Incremental Snapshots: Create efficient, point-in-time copies of your volume for quick recovery.
- Cross-Cluster Backups to S3 or NFS: Protect your data by storing backups off-cluster, which is ideal for disaster recovery.
- Recurring Snapshot and Backup Jobs: Schedule automated protection routines to ensure that backup windows are never missed.
7. What is ReadWriteMany (RWX) access in Longhorn?
RWX allows multiple pods to simultaneously read from and write to the same volume. Longhorn supports RWX by integrating an internal NFS server using the longhorn-share-manager component. This feature is ideal for shared storage scenarios like Content Management Systems (CMSs), shared caches, or collaborative file systems.
8. What is the block I/O stack?
The block I/O stack refers to the series of software layers situated between an application and the storage device. This includes components such as filesystems, buffer caches, I/O schedulers, and device drivers. Traditionally, this stack operates within the kernel and introduces latency. Technologies like SPDK bypass much of this stack, delivering raw performance by handling I/O in user space.
9. Why does each node require open-iscsi and iscsid to be running, along with privileged pod support?
Longhorn presents volumes as iSCSI block devices over the network. The following components are necessary for these reasons:
open-iscsiandiscsidfacilitate each node’s ability to discover and connect to Longhorn volumes.- Some volume operations necessitate direct disk access, so Longhorn runs certain components as privileged pods to securely manage mounting and device handling.
Next Steps
Visit the SUSE solutions Web page here to learn more about SUSE’s cloud native solutions or check out our documentation.
Related Articles
Aug 13th, 2024