There are three levels of interaction or integration between applications and the SUSE Linux Enterprise High Availability (HA) Extension environment.
The most basic level involves no explicit HA interaction for a well-behaved application (active/passive support). The next level is for minimal recognition of the heartbeat and appropriate resource manager use. The third level is for HA function integration into the application code itself.
In the first level, the application should be unaware of and unaffected by the HA environment. The requirements here are mainly that the application is well-behaved for maintaining the state of system functions and resources it uses so that the functions can be properly restarted when needed and that the application should be able to be started and stopped with initscripts that work according to Linux Standard Base requirements for initscripts.
The second level is for the application to be more tightly integrated with the cluster resource manager by providing an Open Clustering Framework (OCF) compliant resource agent.
The third level is to have the application re-architected in a distributed fashion to use the cluster’s interfaces to implement fault tolerance so that it too fails over gracefully and possibly transparently for its end users or jobs.
Application requirements
- General application usage with our High Availability Extension: All applications that may benefit from an application failover between two or more nodes in a high availability cluster can be considered to be made high available using our High Availability Extension. These are typically applications that do not have their own failover mechanisms.
- Distributed applications: Even applications that follow distributed designs (i.e. distributed web application running on web-servers behind load balancers) can profit from running in high availability clusters.
- Application executable: All application executables that run on Linux are supported. This includes all binary application formats as well as all applications that require a runtime environment like a Java virtual machine, shell scripts, Perl and Python.
- Application I/O: There are no limitations on applications’ I/O, as long as they use standard Linux I/O layers and I/O components shipped with SLES (like standard Linux filesystems, cluster filesystem OCFS2, network filesystems, LVM, MD-Raid, etc.). If I/O components are used that are not shipped with SLES or SLE HA, like cluster filesystems other than OCFS2 or GFS2, special care has to be taken. These other I/O components may or may not be usable depending on their 3rd party Pacemaker cluster integrations (i.e., availability of dedicated resource agents).
- Application networking: There are no limitations on the IP networking functionality an application can use. Floating IP addresses (virtual IP addresses) are fully supported, as well as any IP transfer methods like Unicast and Multicast, any IP protocols like TCP, UDP and any other protocols on higher layers like HTTP(S).
- Other cluster layers than Pacemaker: Applications that rely on 3rd party high availability cluster layers or provide their own high availability cluster layers and are not enabled to integrate with the SLE HA cluster stack, may not be usable with our High Availability Extension.
- Dependencies on other applications: If an application A requires the availability of another application B, like a database, special care must be taken to avoid single points of failure. It is required that application B is also controlled by the SLE HA cluster or another high availability cluster or provides its own high availability mechanisms. This is for example the case with Oracle RAC.
- Multiple cluster managers: Only one cluster manager may be active on any given OS instance. Multiple managers must be split into different clusters.
Application control (starting, stopping, monitoring)
- Initscripts:An application running in a Pacemaker high availability cluster requires at least an initscript that fully complies with the LSB initscript specification. It must properly implement start, stop and status functions.
- Systemd Units: SLE HA also supports management of systemd units on SLES 12 and later.
- Resource Agents:A better choice than an initscript is a fully OCF (Open Cluster Framework) compliant resource agent. This is typically a shell script that implements full OCF functionality. More information on OCF resource agents can be found here.
- SLE HA provided scripts,
- other partner-certified script(s),
- the application's own certified script(s).
- Nagios/Icinga probes: SLE HA can utilize installed probes for the popular monitoring systems Nagios or Icinga. While these cannot start or stop services, they can provide additional monitoring insights into the application services.
- Master-/Slave support in applications: Our High Availability Extension supports application designs that implement master-/slave functionality for a reliable and uninterrupted service failover.
Most applications should ship an initscript if they need to be started at system boot time. They're not always "compliant" since often, the system init doesn't really care much about certain corner cases (not fail if stopping a stopped service, the status exit codes, etc.), but that would usually qualify as a bug fix. More information on LSB initscripts can be found here in sections 20.2 and 20.3.
There are many open-source LSB and OCF resource agent scripts available that can be used as templates to develop your own resource agent. Applications may use:
Certification for all three of these is done using the SLE HA "ocf-tester" tooling and information as explained here.
More general HA information can be found here.
Basic application high-availability concepts
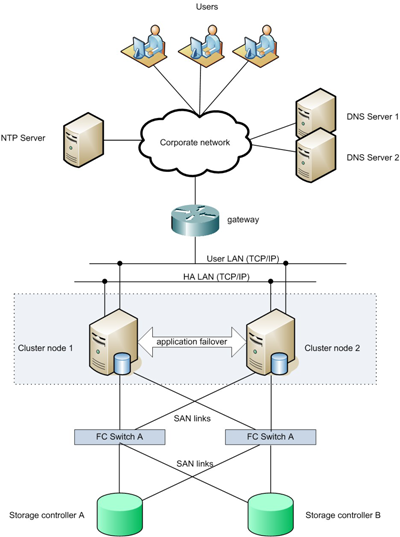
A very common basic high availability cluster architecture consists of two cluster nodes. All physical and logical components are laid out in redundant ways to avoid any SPoF (Single Point of Failure) The cluster is running a single application or an application and a database.
The following figure shows a basic high availability architecture:
Advanced application high-availability concepts:
There are a number of commonly used architectures for advanced high availability cluster setups, e.g., clusters with more than two cluster nodes, active / active or active / passive failover concepts, geo clustering and various of methods data-replication. SUSE and our Consulting partners may help with the architecture and setup of even very complex clusters.