Building Rancher Catalog Templates
Last month
we introduced a new application catalog in the latest versions of
Rancher. The Rancher Catalog provides an easy to use interface that
simplifies deploying Docker-based applications. Using a catalog entry it
becomes simple to deploy complex applications such as Elasticsearch,
Jenkins, Hadoop, as well as tools like etcd and zookeeper, storage
services like GlusterFS, and databases like MongoDB. Already, companies
like Sysdig and others have provided easy to use templates for deploying
their services using Docker. By selecting an entry in the catalog and
answering a few questions allows a user to customize deployments without
having to edit a YAML file or using the command line to deploy a custom
compose file. In this article I’ll walk through how to use the new
catalog function, as well as how to build your own templates and deploy
them to a private catalog. In this month’s Rancher online meetup,
we’ll be diving into this topic in even more detail.
Under the hood
Rancher Catalog is a standalone service that is integrated into the
Rancher UI. The application templates are built on top of
docker-compose.yml files and augmented by the rancher-compose.yml files.
Compose files can be modified by defining configuration questions in the
rancher-compose.yml which ask the user for information at the time of
deployment that then modifies the docker-compose file with the injected
configuration changes. The application templates are versioned and
maintained in a Git repository. This makes it easy to track and approve
updates to the application catalog. Rancher provides a public catalog
with common application offerings that we host in
GitHub. You can also
deploy a custom catalog in the settings tab and point Rancher to your
own alternate Git repository. 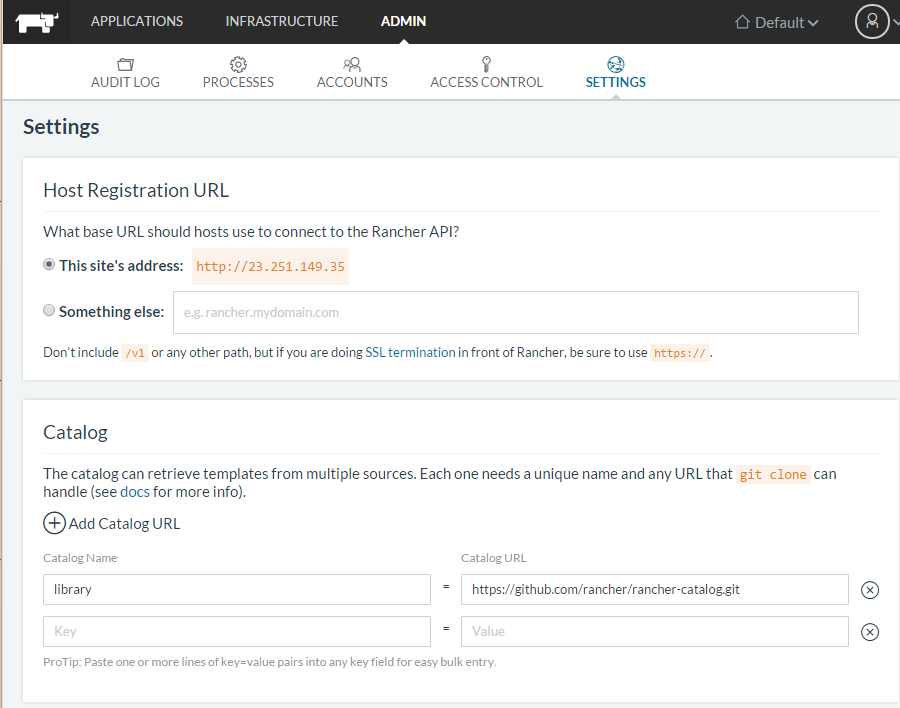
Building application templates
We follow a common pattern when building out new applications, that we
are continuing to refine as we get feedback from users. In this post,
I’d like to share some of the best practices we’ve learned about
building catalog items. When building applications in the catalog, we
make heavy use of Rancher’s Metadata
Service,
DNS
discovery
and sidekick containers. If you’re not familiar with sidekics, they are
containers that are scheduled and deployed together with your primary
container as part of a Rancher service. We use these tools to build
services following the basic ideas below. You can read more about
sidekicks in our docs.
Reuse, Reuse, Reuse!
When we start developing a catalog item we try to begin with an official
image hosted on Docker Hub by the software developer. We have found it
best to use these images as it allows us to leverage the existing work
that goes into updating new versions of the application as they are
released. The key, however is customizing these standard images with
your own configurations.
Use data volume sidekick containers.
Typical we design the services in an application stack using three
containers, one for data volumes, one for configuration and one for the
application itself. The data volume sidekick container holds all of the
data. When upgrading the service, Rancher will not delete the data
volume container (as long as nothing about the data volume container
changed). All of the containers in the service will share the common set
of volumes from this container through a docker volumes_from directive.
Use configuration sidekicks.
This type of container provides a lot of the magic. From this container
we can inject new init scripts and configuration files. You can have
multiple sidekick containers managing configuration, if you have
multiple configuration roles. The files and configuration are passed to
the application through the data volume container or directly from
volumes in the sidekick configuration container. The Rancher Glusterfs
catalog entry is a good example of how to use this technique. Take a
look at the compose file below:
glusterfs-server: image: rancher/glusterfs:v0.1.3 cap_add: - SYS_ADMIN volumes_from: - glusterfs-data labels: io.rancher.container.hostname_override: container_name io.rancher.sidekicks: glusterfs-peer,glusterfs-data,glusterfs-volume-create command: "glusterd -p /var/run/gluster.pid -N" glusterfs-peer: image: rancher/glusterfs:v0.1.3 net: 'container:glusterfs-server' volumes_from: - glusterfs-data labels: io.rancher.container.hostname_override: container_name command: /opt/rancher/peerprobe.sh glusterfs-data: image: rancher/glusterfs:v0.1.3 command: /bin/true volumes: - /var/run labels: io.rancher.container.hostname_override: container_name io.rancher.container.start_once: true glusterfs-volume-create: image: rancher/glusterfs:v0.1.3 command: /opt/rancher/replicated_volume_create.sh net: 'container:glusterfs-server' volumes_from: - glusterfs-data labels: io.rancher.container.hostname_override: container_name io.rancher.container.start_once: true
There is a lot going on there, so lets just focus on the sidekicks. You
can see that glusterfs-server has three sidekicks one for data, one to
handle peer probing, and one to handle volume creation. The peer probe
and volume creation containers are both configuration containers and
serve unique non-overlapping roles in the creation of the stack. Also,
the volume create container is only needed on the initial configuration
steps. Once it is started it stops and no longer consumes resources.
One process / function per container.
In the most common case we deploy the app, configuration and data
containers. In some cases though, running the app and getting it into a
usable state requires additional steps. Take GlusterFS as an example. As
new Gluster server containers come up they need to peer probe into the
cluster. To handle new containers joining, we created a container that
monitors metadata and does peer probing. This peer probing container
sits alongside the standard data and configuration sidekicks. The
catalog is a powerful feature in Rancher, making it easier for teams to
deploy commonly used applications. To get started building your own
catalog, you can follow the
docs
here and be up and running with a catalog of your own applications. If
your looking for examples to follow, take a look at the templates in the
official
arancher-catalog on
GitHub. Next week we’ll be demonstrating how to build these stacks on
our monthly online meetup. Please join us to get a hands-on
overview.
Related Articles
Nov 29th, 2022
Installing and Running Kubewarden In Air-Gapped Environments
Apr 29th, 2022