Untangling Kubernetes: The Steep Climb of Deployment and Day 2 Operations
Co-authored with Chris Crow | Sr. Technical Marketing Manager, Pure Storage
Kubernetes. The name itself evokes images of scalability, resilience, and cloud-native agility. It has undeniably become the de facto standard for container orchestration, promising a future where applications can be deployed and managed consistently across any environment. But beneath the powerful abstraction lies a significant operational complexity, particularly when it comes to initial deployment (Day 1) and, even more critically, the ongoing management (Day 2).
While the idea of Kubernetes is elegant, the reality of running it in production often involves a steep learning curve and a surprising amount of manual effort, without solutions that can streamline the operational complexity. Let’s break down why.
The Day 1 Hurdle: More Than Just kubeadm init
1. Standing Up Kubernetes: Why Day 0 Is More Than Just “Installation”
Getting your first Kubernetes cluster running isn’t just a matter of installing software. It’s a deeply involved process requiring dozens of infrastructure, networking, and security decisions, each with significant implications for both platform and development teams.
2. Infrastructure Provisioning
Choosing where your cluster will run — whether on-premises VMs, cloud instances like EC2 or GKE, or bare metal — isn’t a one-size-fits-all decision. Each option brings its tooling, provisioning workflows, and integration points.
Impact: For platform teams, this means navigating different APIs, provisioning scripts, and automation strategies. For developers, delays in cluster availability can stall application timelines, particularly when environments aren’t consistent across teams.
3. Network Configuration
Selecting and configuring a Container Network Interface (CNI) plugin such as Calico, Flannel, or Cilium is crucial for enabling pod-to-pod communication. It requires a solid understanding of subnetting, routing, and network policies, and must align with the organization’s existing network infrastructure.
Impact: Platform teams face a high risk of misconfiguration that can break workloads, while developers often encounter connectivity issues they’re unequipped to diagnose.
4. Control Plane Setup
Installing Kubernetes core components like the API server, etcd, scheduler, and controller manager involves sensitive decisions around high availability, security (e.g., TLS certs), and performance tuning.
Impact: If the control plane isn’t resilient, it becomes a single point of failure. Platform teams bear the burden of getting this right, and developers experience the consequences — from unreliable deployments to sporadic outages.
5. Worker Node Joining
Each node must be correctly configured with a container runtime (like containerd), kubelet, and kube-proxy, and then securely joined to the control plane. This requires version alignment, credential handling, and secure transport.
Impact: For infra teams, this is yet another manual process prone to errors. When nodes fail to join or drift from the desired state, developers face failed deployments and wasted debugging time.
6. Security Hardening
Implementing RBAC, network policies, secret management, and authentication flows isn’t optional — it’s foundational. But it’s also complex and easy to get wrong.
Impact: Infra teams must strike a balance between security and usability, while developers can be blocked entirely if access isn’t provisioned correctly or policies are too restrictive.
7. Essential Add-ons
A working cluster doesn’t mean a usable one. Platform teams must layer on ingress controllers, observability stacks (e.g., Prometheus/Grafana), logging solutions, and certificate management — each requiring additional Helm charts, CRDs, and configuration.
Impact: Until these are in place, developers lack the visibility, routing, and reliability they need to deploy and monitor apps effectively.
Each of these steps requires deep technical knowledge, careful execution, and significant time investment. Errors made during Day 1 can lead to instability, security vulnerabilities, and major headaches down the line.
The Even Steeper Climb: Navigating Day 2 Operations
Congratulations — your Kubernetes cluster is up and running. But now comes the real work. Day 2 operations encompass everything needed to keep the cluster healthy, secure, performant, and cost-effective over time. This is where complexity increases dramatically, and both platform and development teams face ongoing operational, technical, and organizational pressure.
- Monitoring and Alerting
Observability is a foundational Day 2 concern. Teams must set up cluster-wide monitoring covering nodes, the control plane, workloads, and resource consumption. Alerting systems must distinguish between minor fluctuations and real incidents to avoid alert fatigue. Maintaining and tuning these systems is a continuous effort.
Impact: Platform teams spend significant time on visibility tooling just to keep the lights on, while developers often face poor insight into performance issues, delaying troubleshooting and increasing time to resolution. - Logging and Auditing
Centralized logging ensures traceability and enables security audits. Implementing solutions like EFK or Loki stacks requires platform teams to manage storage, retention, indexing, and access control. Developers depend on this infrastructure to understand how their applications behave across environments.
Impact: When logging isn’t robust, platform teams waste time hunting down logs across nodes, and developers are blocked when they can’t access the insights needed to debug or verify application behavior. - Upgrades and Patching
Kubernetes evolves quickly, with new releases introducing improvements and breaking changes. Keeping clusters updated involves compatibility checks, planned downtime, and staged rollouts, plus OS and kernel patching. Even with automation, the process is risky.
Impact: Platform teams are under pressure to upgrade quickly for security and support, while developers may encounter breaking changes or downtime that derail feature delivery or introduce regressions. - Scaling (Nodes and Applications)
As demand fluctuates, clusters must scale. Platform teams manage node pools and autoscaler configurations, while developers must correctly specify resource requests, limits, and HPAs for their applications. Without coordination, scaling can either fail or result in resource waste.
Impact: Platform teams must firefight capacity issues or deal with inflated costs due to over-provisioning, while developers face performance bottlenecks or throttling when scaling is misconfigured. - Security and Compliance Management
Keeping clusters secure requires continuous vulnerability scanning, RBAC management, TLS certificate rotation, and enforcement of policies like PodSecurity or Admission Controllers. These practices often lag behind the application deployment pace.
Impact: Platform teams are overwhelmed trying to enforce standards without slowing innovation, and developers become frustrated when unclear or shifting policies block deployments or break apps. - Backup and Disaster Recovery
Ensuring backup of etcd and persistent application data is non-negotiable. Platform teams must deploy and maintain backup solutions, test restores, and align recovery strategies with RTO/RPO goals. Developers need confidence that their services won’t lose critical data during failures.
Impact: Platform teams bear the burden of setting up and verifying complex backup workflows, while developers are often unsure what will happen to their workloads during outages, creating anxiety and limiting experimentation. - Multi-Cluster Management
With Kubernetes adoption, multiple clusters emerge—dev, test, prod- across clouds and geographies. Keeping policies, monitoring, access, and upgrades consistent across them is a huge lift. Developers must interact with different environments that often behave differently.
Impact: Platform teams face operational sprawl and tool fragmentation, while developers encounter inconsistencies that lead to bugs in production and increased onboarding complexity. - Cost Management and Optimization
Kubernetes introduces hidden costs—especially around persistent volumes. Infra teams may over-provision storage, or fail to clean up unused volumes, driving up cloud bills. Developers, meanwhile, may request more storage than needed due to poor usage visibility.
Impact: Platform teams are tasked with monitoring and justifying growing storage expenses, while developers are often forced into disruptive cleanup cycles that slow down feature delivery and reduce velocity. - Data Resilience and Stateful Workload Management
Applications with persistent data, like databases or AI workloads, are especially sensitive to failures. Platform teams must ensure data is backed up, portable, and recoverable. Developers must build apps that can tolerate failover and resume stateful operations safely.
Impact: Without coordinated processes, platform teams risk data loss or corruption during recovery, and developers are left guessing how their app behaves under failure, leading to production incidents and lost trust.
- Hybrid and Multi-Cloud Complexity
Running Kubernetes across on-prem, cloud, and edge environments introduces divergent networking models, storage systems, and security policies. Platform teams must unify observability, backups, identity, and storage behaviors. Developers must adapt to different APIs and performance profiles across environments.
Impact: Platform teams must maintain complex, duplicated infrastructure and configurations, while developers lose productivity adapting to subtle differences between platforms, limiting portability and innovation
Solving the Data Challenges
Across all these Day 2 concerns, data introduces some of the most persistent and complex challenges. Kubernetes wasn’t originally designed with stateful applications in mind, and while CSI has provided a standardized interface, critical enterprise features like granular backup and restore, storage tiering, multi-cloud migration, and zero-downtime failover remain unsolved at the platform level.
Storage costs spiral as volumes are over-provisioned or orphaned. Backup workflows are often cobbled together with multiple tools and scripts. Migrating stateful applications between clusters or regions — especially across clouds — is error-prone and time-consuming. Developers, meanwhile, have little visibility into volume performance or reliability, and often lack the tools to test how their applications behave during storage failures or recovery scenarios.
Taming the Beast: Enter SUSE Rancher Prime
This is precisely where a Kubernetes management platform like SUSE Rancher Prime provides immense value. It’s designed specifically to abstract away much of this Day 1 and Day 2 complexity for the platform itself, allowing teams to focus on applications rather than infrastructure plumbing.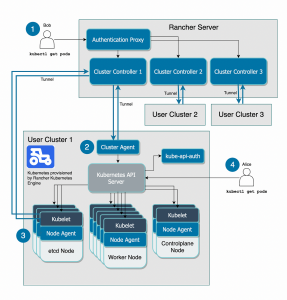
Figure 1: SUSE Rancher Prime provides a unified management plane for Kubernetes clusters across On-Premises, Public Cloud, and Edge environments, centralizing key functions like Authentication, Cluster Management, App Catalogs, and Monitoring.
Here’s how SUSE Rancher Prime addresses the platform challenges:
Simplified Cluster Provisioning: SUSE Rancher Prime offers push-button deployment for Kubernetes clusters across various providers (public cloud, vSphere, bare metal) using RKE (Rancher Kubernetes Engine) or by importing existing clusters (like EKS, GKE, AKS). It handles the intricacies of component installation, networking setup, and initial configuration.
Unified Multi-Cluster Management: Its core strength lies in providing a single pane of glass to manage all your Kubernetes clusters, regardless of where they run. This centralizes visibility and control.
Centralized Authentication & RBAC: Integrate with existing identity providers (AD, LDAP, SAML) and enforce consistent RBAC policies across all managed clusters from one location.
Integrated Tooling: SUSE Rancher Prime comes pre-packaged and integrated with essential Day 2 tools for monitoring (Prometheus, Grafana), logging (Fluentd), and service mesh (Istio), simplifying their deployment and management.
Streamlined Upgrades: SUSE Rancher Prime simplifies the cluster upgrade process, automating many steps and reducing the associated risks and manual effort.
Global Application Catalog: Deploy applications consistently across clusters using Helm charts managed through a central catalog.
Policy Enforcement: Use tools like OPA Gatekeeper, integrated via SUSE Rancher Prime, to enforce security and configuration policies across your fleet.
SUSE Rancher Prime simplifies Day 2 Kubernetes operations by delivering a unified platform that directly benefits both infrastructure and development teams. For infra teams, Rancher automates cluster provisioning, upgrades, security patching, and policy enforcement across hybrid and multi-cloud environments — dramatically reducing manual overhead and operational risk. At the same time, it empowers developers with self-service access to compliant, production-ready Kubernetes clusters, so they can build and deploy faster without waiting on infrastructure tickets. Built-in observability, RBAC, and centralized governance ensure both teams have the visibility and control they need, fostering better collaboration and freeing up time for innovation instead of firefighting.
However, managing storage for stateful applications within Kubernetes introduces another layer of complexity. This is where Portworx by Pure Storage comes in. Designed from the ground up for Kubernetes-native stateful workloads, Portworx provides highly available, performant, and portable storage. It solves key Day 2 data challenges by enabling features like automated backups, application-aware snapshots, disaster recovery, multi-cluster volume replication, and storage cost optimization — all integrated within Kubernetes workflows. For platform teams, this means simplified operations and consistent policy enforcement. For developers, it means confidence in deploying resilient applications across environments.
In our next blog, we’ll explore how SUSE Rancher Prime and Portworx together create a powerful, production-grade platform for modern applications — one that unifies Day 2 operations for both infrastructure and application teams. From GitOps-driven deployment pipelines to automated storage lifecycle management, we’ll walk through real-world strategies to tame complexity and accelerate innovation.
Related Articles
Mar 11th, 2025